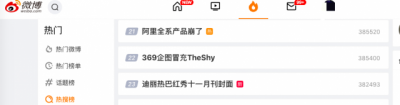
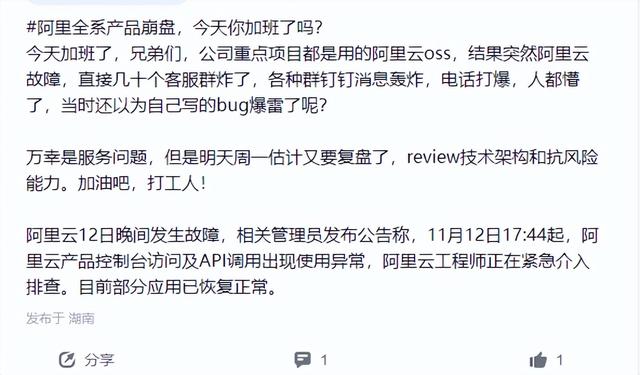
2023年11月12日17:44分,阿里云遭遇了一场罕见的大规模故障,全国多个地域的云产品控制台访问及API调用出现异常,影响了阿里云的核心业务,包括淘宝、闲鱼、钉钉等。这场故障持续了近两个小时,期间,阿里云的工程师们紧急介入排查和处理,最终在19:20分左右,恢复了正常服务。这场故障引发了广泛的关注和讨论,有不少人质疑阿里云的技术能力和服务质量,担心阿里云的客户会为此付出巨大的损失。那么,阿里云的故障究竟是怎么发生的,又是谁之过呢?

根据官方媒体的通报,故障的原因是与某个底层服务组件有关。笔者猜测可能是因为该组件主要负责提供云产品控制台的访问和API调用的能力,相关配置文件被错误地修改,导致了组件的不稳定和异常。因此,当该组件出现故障时,就会影响到所有依赖于该组件的云产品的正常使用。阿里云的工程师们在发现故障后,立即进行了排查和处理,通过分批重启组件服务,逐步恢复了各个地域的控制台服务,事故持续时间长达近两小时。

对此,不少阿里云的使用方都在吐槽业务崩溃、被工作群的消息轰炸,还以为自己写的bug爆雷了。如果这次故障按照SLA赔偿(如服务可用性低于 99.95%,用户可获得月度服务费 10%、25%、100% 不等的赔偿),企业端的服务估计可以获赔一大笔金额,毕竟对业务的影响是实实在在的。
阿里云作为国内最大的云服务提供商,拥有超过60%的市场份额,服务了数以亿计的客户和用户,其技术实力和服务质量是有目共睹的。此次故障虽然影响范围甚广,但是可以预见的是并不会造成特别严重的损失和影响,只是不少企业会重新评估是否还要继续使用阿里云的服务,毕竟云计算的核心是稳定,其次才是性能。

此次故障更应该被视为一次警示和教训,提醒阿里云和其他的云服务提供商,要加强对云产品的管理和监控,防止类似的故障再次发生,同时,要提高对客户和用户的服务水平和满意度,赢得更多的信任和支持。
|