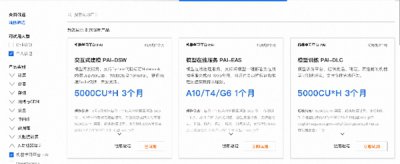
ǰ��
���ڣ�Meta ����������ģ�� Llama2 ��Դ������7B��13B��70B��ͬ�ߴ磬�ֱ��Ӧ70�ڡ�130�ڡ�700�ڲ�����������ÿ������¶���ר������Ի��������Ż�ģ��Llama-2-Chat��Llama2 ����������о���������ҵ��;�����»��7�����ϵ���ҵ��Ҫ���룩������ҵ�Ϳ�������˵���ṩ�˴�ģ���о�������������
Ŀǰ��Llama-2-Chat�ڴ��������ָ���ϳ�����������Դ�Ի�ģ�ͣ�����һЩ���ű�Դģ�ͣ�ChatGPT��PaLM���������ƻ���ѧϰƽ̨PAI��һʱ����� Llama2 ϵ��ģ�ͽ������䣬�Ƴ�ȫ������Lora������������ȳ������ʵ��������AI�����߿��ٿ��䡣�������ǽ��ֱ�չʾ����ʹ�ò��衣
���ʵ��һ��Llama 2 �ʹ��� Lora ��������
��ʵ�������ð���������ѧϰƽ̨PAI-���ٿ�ʼģ����� Llama-2-7b-chat ���п�����PAI-���ٿ�ʼ֧�ֻ��ڿ�Դģ�͵ĵʹ���ѵ�������������ȫ���̣��ʺ���Ҫ���ٿ�������Ԥѵ��ģ�͵Ŀ����ߡ�
һ��������
1������PAI-���ٿ�ʼҳ��
a. ����PAI����̨ https://pai.console.aliyun.com/
b. ����PAI�����ռ䣬������ർ�������ҵ�“���ٿ�ʼ”��

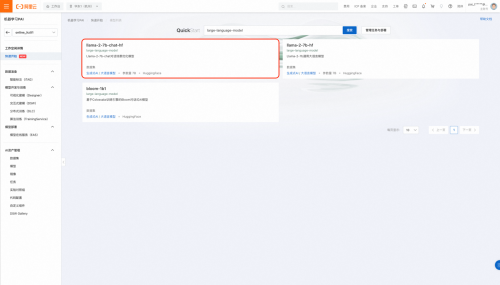
2��ѡ��Llama2ģ��
PAI-���ٿ�ʼ�����˲�ͬ��Դ���������ſ�Դģ�ͣ���֧���˹����ܵIJ�ͬ����������ڱ���ʵ���У���ѡ��“����ʽAI-������ģ�ͣ�large-language-model��”������ģ���б�ҳ��

��ģ���б�ҳ�������Կ���������Բ�ͬ��Դ����������ģ�͡��ڱ���չʾ�У����ǽ�ʹ��llama-2-7b-chat-hfģ�ͣ�llama-2-7b-hfģ��ͬ��������Ҳ��������ѡ�������ʺ�����ǰҵ�������ģ�͡�
Tips��
һ����˵��������Խ���ģ��Ч������ã������Ӧ��ģ������ʱ�����ķ��ú���ѵ������Ҫ��������������ࡣ
Llama-2-13B��70B�İ汾���Լ�������Դ������ģ��Ҳ��������PAI-���ٿ�ʼ���ߣ������ڴ���
����ģ����������
���ٿ�ʼ�ṩ��llama-2-7b-chat-hf��Դ��HuggingFace�ṩ��Llama-2-7b-chatģ�ͣ���Ҳ����Ҫ����Transformer�ܹ��Ĵ�����ģ�ͣ�ʹ�ö��ֻ�ϵĿ�Դ���ݼ�����ѵ��������ʺ����ھ��������Ӣ�ķ�רҵ���������ǿ���ͨ��PAI���ٿ�ʼ����ģ��ֱ�Ӳ���PAI-EAS������һ����������
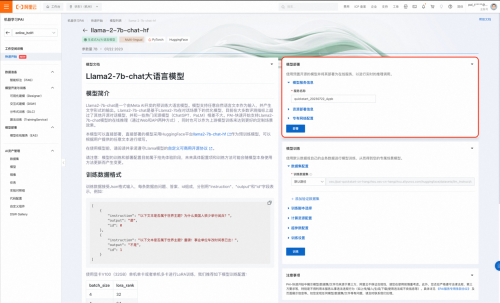
1������ģ��
ͨ��ģ������ҳ��ĵIJ������������һ������һ�����ڴ�ģ�͵����������������еIJ����Ѿ�����Ĭ��������ϡ���Ȼ����Ҳ��������ѡ����ʹ�õļ�����Դ���������ã����Ǽ����Խ���ģ��ֱ�Ӳ���PAI-EAS������������
��ע�⣬ģ����Ҫ����64GiB�ڴ��24GiB�����ϵ��Դ棬��ȷ����ѡ��ļ�����Դ��������Ҫ���������ʧ�ܡ�
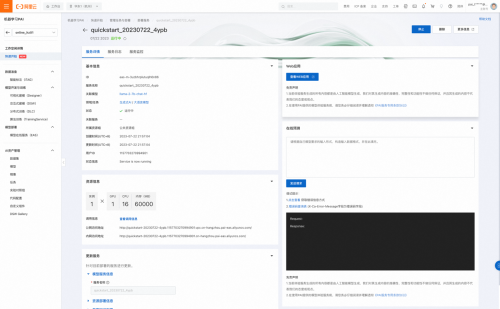
ͨ����������ҳ�������Բ鿴��������IJ���״̬��������״̬Ϊ“������”ʱ����ʾ���������Ѿ�����ɹ���
Tips��
������������ʱ��PAI-���ٿ�ʼ�е��“���������벿��”��ť���ص���ǰ����������
2��������������
�ڲ���ɹ�֮��������ͨ��WebUI�ķ�ʽ������ٶȵ������ķ�����Ԥ������
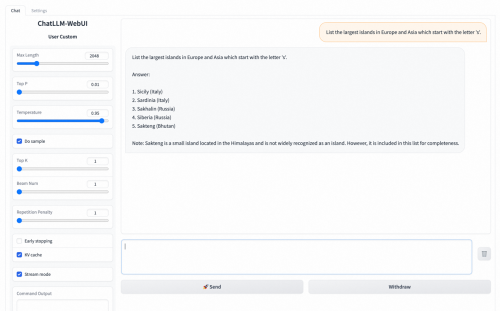
��WebUI��Ҳͬʱ֧����API��������������ĵ�������WebUIҳ���“Use via API”�鿴��
����ģ����ѵ��
llama-2-7b-chat-hfģ�������ھ��������רҵ�ij�����������ҪӦ���ض������רҵ֪ʶʱ��������ѡ��ʹ��ģ�͵���ѵ��������ģ�����Զ��������������
Tips��
������ģ��Ҳ�����ڶԻ�������ֱ��ѧϰ���Ƚϼ�֪ʶ��������Լ�������ѡ���Ƿ�ѵ����
��ǰ���ٿ�ʼ֧�ֵ�ѵ����ʽ����LoRA��LoRAѵ�����������ѵ����ʽ����SFT�ȣ�����������ѵ���ɱ���ʱ�䣬��������ģ�͵�LoRAѵ��Ч�����ܲ��ȶ���
1��������
Tips��
Ϊ��������������Llama 2ģ�ͣ������� llama-2-7b-chat-hf��ģ�Ϳ�Ƭ��Ҳ�Ѿ���������һ��Ĭ������Instruction Tuning�����ݼ���ֱ�ӽ�����ѵ����
ģ��֧��ʹ��OSS�ϵ����ݽ���ѵ����ѵ�����ݽ���Json��ʽ���룬ÿ�����������⡢�𰸡�id��ɣ��ֱ���"instruction"��"output"��"id"�ֶα�ʾ�����磺
[
{
"instruction": "�����ı��Ƿ������������⣿Ϊʲô�����˺��پ����ı���",
"output": "��",
"id": 0
},
{
"instruction": "�����ı��Ƿ������������⣿�ذ�����ҵ��λ����ʱ����ѳ���",
"output": "����",
"id": 1
}
]
ѵ�����ݵľ����ʽҲ������PAI-���ٿ�ʼ�ľ���ģ�ͽ���ҳ�в��ġ�
��������ϴ����ݵ�OSS���Լ��鿴��Ӧ�����ݣ���ο�OSS�İ����ĵ���https://help.aliyun.com/document_detail/31883.html?spm=a2c4g.31848.0.0.71102cb7dsCgz2
Ϊ�˸��õ���֤ģ��ѵ����Ч���������ṩѵ�����ݼ�֮�⣬Ҳ�Ƽ�����һ����֤���ݼ���������������ѵ��������ģ��ѵ����Ч�����Լ�ѵ���IJ����Ż�������
2���ύѵ����ҵ
������ʹ�õ����ݼ�֮�����������ڿ��ٿ�ʼ��ģ��ҳ������ѵ��ʹ�õ����ݼ����ύѵ����ҵ�������Ѿ�Ĭ���������Ż����ij�������ѵ����ҵʹ�õļ�����Դ���ã���Ҳ���Ը����Լ���ʵ��ҵ���ġ�
ͨ��ѵ����ҵ����ҳ�������Բ鿴ѵ�������ִ�н��ȡ�������־���Լ�ģ�͵�������Ϣ����ѵ�������״̬Ϊ“�ɹ�”��ѵ����ҵ������ģ�ͻᱻ���浽OSS�ϣ�����ҵ����ҳ��“ģ�����·��”����
Tips��
ʹ��Ĭ�����ݼ���Ĭ�ϳ�������������Դѵ�����Ԥ�Ƶ����ʱ����1Сʱ30�������ҡ����ʹ���Զ���ѵ�����ݺ������Ԥ�Ƶ�ѵ�����ʱ������������죬��ͨ��Ӧ������Сʱ����ɡ�
�����;�ر���ҳ�棬��������ʱ��PAI-���ٿ�ʼ�е��“���������벿��”��ť���ص���ǰ��ѵ������
3��������ģ��
����ѵ���ɹ�֮���û�����ֱ������ҵ����ҳ����õ�ģ�Ͳ���Ϊ�����������ģ�Ͳ���ͷ������������������ϵ�“ֱ�Ӳ���ģ��”���ĵ���
���ʵ������Llama2 ȫ������ѵ��
��ʵ�������ð���������ѧϰƽ̨PAI-DSWģ����� Llama-2-7B-Chat ����ȫ��������PAI-DSW�ǽ���ʽ��ģƽ̨����ʵ���ʺ���Ҫ���ƻ���ģ�ͣ�����ģ�͵���Ч���Ŀ����ߡ�
һ�����л���Ҫ��
Python����3.9���ϣ�GPU�Ƽ�ʹ��A100��80GB��������Դ�ȽϽ��Σ������ˢ�¼��Ρ�
����������
1������PAI������ Llama-2-7B-Chat
a. ����PAI����̨ https://pai.console.aliyun.com/
b. ���� PAI-DSW ����ʵ��������ģ���ļ����������´��룬�����Զ�Ϊ��ѡ����ʵ����ص�ַ������ģ�����ص���ǰĿ¼��
import os
dsw_region = os.environ.get("dsw_region")
url_link = {
"cn-shanghai": "https://atp-modelzoo-sh.oss-cn-shanghai-internal.aliyuncs.com/release/tutorials/llama2/llama2-7b.tar.gz",
"cn-hangzhou": "https://atp-modelzoo.oss-cn-hangzhou-internal.aliyuncs.com/release/tutorials/llama2/llama2-7b.tar.gz",
"cn-shenzhen": "https://atp-modelzoo-sz.oss-cn-shenzhen-internal.aliyuncs.com/release/tutorials/llama2/llama2-7b.tar.gz",
"cn-beijing": "https://atp-modelzoo-bj.oss-cn-beijing-internal.aliyuncs.com/release/tutorials/llama2/llama2-7b.tar.gz",
}
path = url_link[dsw_region]
os.environ['LINK_CHAT'] = path
!wget $LINK_CHAT
!tar -zxvf llama2-7b.tar.gz
������ĵ����������������У�����������ѡ�����������������ӽ�������(��ͬ�������������ǵý������е�-internalȥ��)��ͬһ��������������ٶȿ죬��ͬ����֮��Ҳ�������أ������ٶȱ�ͬһ����������
�����ϣ����ModelScope����ģ�ͣ��������ӣ�https://modelscope.cn/models/modelscope/Llama-2-7b-chat-ms/summary
2�����غͰ�װ����
�������غͰ�װ����Ҫ�Ļ�����
ColossalAI�Ǵ��ģ����AIѵ��ϵͳ���ڱ���������ʹ�øÿ�ܽ���ģ������
transformers�ǻ���transformersģ�ͽṹ��Ԥѵ�����Կ⡣
gradio��һ�����ٹ�������ѧϰWebչʾҳ��Ŀ�Դ�⡣
! wget https://atp-modelzoo-sh.oss-cn-shanghai.aliyuncs.com/release/tutorials/llama2/ColossalAI.tar.gz
! tar -zxvf ColossalAI.tar.gz
! pip install ColossalAI/.
! pip install ColossalAI/applications/Chat/.
! pip install transformers==4.30.0
! pip install gradio==3.11
3������ʾ��ѵ������
����ѵ����������ݣ����������ṩ��һ�ݴ����������ݣ��������Ը����ɵ����ݡ�
��Ҳ���Բο��ø�ʽ���������������ݡ�
! wget https://atp-modelzoo-sh.oss-cn-shanghai.aliyuncs.com/release/tutorials/llama2/llama_data.json
! wget https://atp-modelzoo-sh.oss-cn-shanghai.aliyuncs.com/release/tutorials/llama2/llama_test.json
������ģ��
������ʹ���Ѿ�д�õ�ѵ���ű�������ģ��ѵ����
! sh ColossalAI/applications/Chat/examples/train_sft.sh
�ġ�����ģ��
ģ��ѵ����ɺ����������ṩ��webUI demo����������ɵ�ģ�ͣ�ע��ģ�͵�ַ�滻Ϊ�Լ�ѵ���õ�ģ�͵�ַ����
import gradio as gr
import requests
import json
from transformers import AutoTokenizer, AutoModelForCausalLM
#ģ�͵�ַ�滻Ϊ�Լ�ѵ���õ�ģ�͵�ַ
tokenizer = AutoTokenizer.from_pretrained("/mnt/workspace/sft_llama2-7b",trust_remote_code=True)
#ģ�͵�ַ�滻Ϊ�Լ�ѵ���õ�ģ�͵�ַ
model = AutoModelForCausalLM.from_pretrained("/mnt/workspace/sft_llama2-7b",trust_remote_code=True).eval().half().cuda()
def inference(text):
from transformers import pipeline
pipe = pipeline("text-generation", model=model, tokenizer=tokenizer,device='cuda:0', max_new_tokens=400)
res=pipe(text)
return res[0]['generated_text'][len(text):]
demo = gr.Blocks()
with demo:
input_prompt = gr.Textbox(label="����������", value="������������ʦ�����ݣ�дһƪ��ְ�ķ��Ը塣", lines=6)
generated_txt = gr.Textbox(lines=6)
b1 = gr.Button("����")
b1.click(inference, inputs=[input_prompt], outputs=generated_txt)
demo.launch(enable_queue=True, share=True)
�塢ģ���ϴ���OSS�����߲���
���ϣ��������ģ�Ͳ�����PAI-EAS������Ҫ���Ƚ�ѵ����ɵ�ģ���ϴ���OSS��
���в�����Ҫ�������Լ�����Ϣ��д
# encoding=utf-8
import oss2
import os
AK='yourAccessKeyId'
SK='yourAccessKeySecret'
endpoint = 'yourEndpoint'
dir='your model output dir'
auth = oss2.Auth(AK, SK)
bucket = oss2.Bucket(auth, endpoint, 'examplebucket')
for filename in os.listdir(dir):
current_file_path = dir+filename
file_path = '��Ҫ�ϴ���ַ'
bucket.put_object_from_file(file_path, current_file_path)
���������в�������������ο������ʵ������Llama2 ���ٲ��� WebUI��
���ʵ������Llama2 ���ٲ��� WebUI
��ʵ�������ð���������ѧϰƽ̨PAI-EASģ����� Llama-2-13B-chat ���в���PAI-EAS��ģ�����߷���ƽ̨��֧�ֽ�ģ��һ������Ϊ�������������AI-WebӦ�ã��߱������������ص㣬�ʺ�������Լ۱�ģ�ͷ���Ŀ����ߡ�
һ��������
����PAI-EASģ�����߷���ҳ�档
a.��¼PAI����̨ https://pai.console.aliyun.com/
b.����ർ�������������ռ��б����ڹ����ռ��б�ҳ���е����������Ĺ����ռ����ƣ������Ӧ�����ռ��ڡ�
c.�ڹ����ռ�ҳ�����ർ����ѡ��ģ�Ͳ���>ģ�����߷���EAS��������PAI EASģ�����߷���ҳ�档
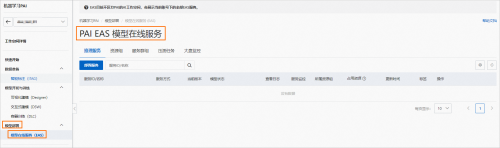
2����PAI EASģ�����߷���ҳ�棬�����������
3���ڲ������ҳ�棬�������¹ؼ�������
|
����
|
����
|
|
��������
|
�Զ���������ơ�������ʹ�õ�ʾ��ֵΪ��chatllm_llama2_13b��
|
|
����ʽ
|
ѡ��������AI-WebӦ����
|
|
����ѡ��
|
��PAIƽ̨�����б���ѡ��chat-llm-webui������汾ѡ��1.0��
���ڰ汾����Ѹ�٣�����ʱ����汾ѡ����߰汾���ɡ�
|
|
��������
|
�����������
���ʹ��13b��ģ�ͽ��в���python webui/webui_server.py --listen --port=8000 --model-path=meta-llama/Llama-2-13b-chat-hf --precision=fp16
���ʹ��7b��ģ�ͽ��в���python webui/webui_server.py --listen --port=8000 --model-path=meta-llama/Llama-2-7b-chat-hf
�˿ں����룺8000
|
|
��Դ������
|
ѡ��������Դ����
|
|
��Դ���÷���
|
ѡ��������Դ������
|
|
��Դ����ѡ��
|
����ѡ��GPU���ͣ�ʵ������Ƽ�ʹ��ecs.gn6e-c12g1.3xlarge��
13b��ģ���������gn6e�����߹��Ļ����ϡ�
7b��ģ�Ϳ�������A10/GU30�����ϡ�
|
|
����ϵͳ��
|
ѡ��50GB
|
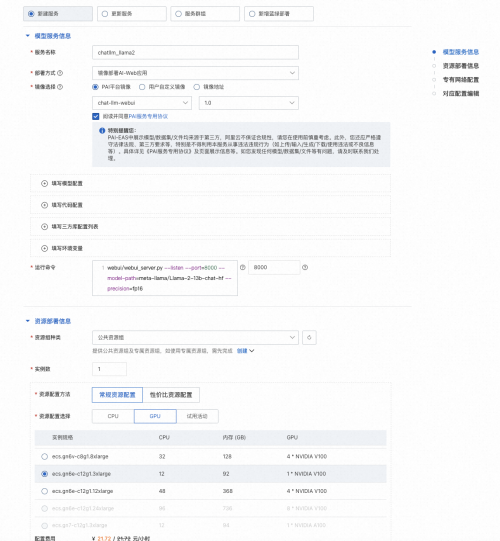
4���������𣬵ȴ�һ��ʱ�伴�����ģ�Ͳ���
��������WebUI����ģ������
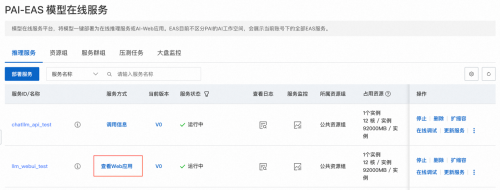
1������Ŀ�����ķ���ʽ���µIJ鿴WebӦ�á�
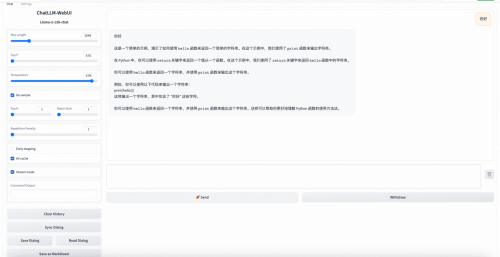
2����WebUIҳ�棬����ģ��������֤��
�ڶԻ����·��������������Ի����ݣ�����”���ṩһ������ѧϰ�ƻ�”��������ͣ����ɿ�ʼ�Ի���
What's More
1.������Ҫչʾ�˻��ڰ����ƻ���ѧϰƽ̨PAI���ٽ���Llama2������������ʵ������Ҫ������7B��13B�ߴ�ġ����������ǽ�չʾ��λ���PAI����70B�ߴ�� Llama-2-70B �������������������ڴ���
2.����ʵ���У������ʵ������Llama2 ���ٲ��� WebUI��֧��������û������У���ӭ������Ķ�ԭ�ġ�ǰ��������ʹ��������ȡ“PAI-EAS”������ú�ǰ��PAI����̨���顣
�ο����ϣ�
Llama2: Inside the Model https://ai.meta.com/llama/#inside-the-model
Llama 2 Community License Agreement https://ai.meta.com/resources/models-and-libraries/llama-downloads/
HuggingFace Open LLM Leaderboard https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard
�����ƻ���ѧϰƽ̨PAI��https://www.aliyun.com/product/bigdata/learn
�ر���ʾ�� Llama2 ���ڹ��˾�����������Կ�Դģ�ͣ����������ʹ��ǰ��ϸ�Ķ������� Llama2 ������Э�飬������������������������»��7�����ϵ���ҵ������������ɣ�����������ȡ�
��������������������ù��ҵķ��ɷ��棬�������� Llama2 ���й����ڹ����ṩ���������ع��ҵĸ���ɷ���Ҫ�����䲻�ô��»�����Σ�����ҡ���ᡢ����Ȩ�����Ϊ�����ݡ�
|