�����ѳ�Ϊ�ƶ���ҵ����ҵ����ҵ��չ�ľ��ƶ�������Ϊ“���ݼ�ֵ������”������ƽ̨����ҵ������ϵ�Ĺؼ�һ����������ҵ�Ż����ݹ������ṩ���ݷ������߽��飬����ʵ�������ʲ�����
�ӻ����������ٵ���ģ�ͣ�һ�������������˳�������ָ�������ǵ�������������ҵ�ڹ�������ƽ̨ʱ��ҪͶ�����������ɱ���ʱ��ɱ��Ͳ���ɱ������ܸ���ҵ��չ������Ȼ��������ƽ̨�ܹ����Ӷȸߡ������ɱ��ߣ�����ҵ���ݼ�ֵ������ֻ�ת�ͽ���������ƿ��������ƽ̨��ν���ʹ�ü����ż���������ҵ��Ӫ�ɱ����������ݷ�������������ݼ�ֵ��ƽ̨��ҵ�����ٵĺ������⡣
7 �� 20 �գ������Ƽ������״ζ���IJ�Ʒ�����ᣬ�״��Ƴ���һ��“���ơ�һ�廯”������ƽ̨���� Lakehouse��������������·�ʽ���������������㹹�� “Single-Engine”һ�廯ƽ̨���ں��ּܹ�֮�ϣ�ʵ�����������������ַ���ģʽ��ͳһ��Ϊ��ҵ�ṩ���伴�á������ܡ��ͳɱ�������ƽ̨��������ҵ���������ݱ�Ϊ����������Ƽ������ֻ���ҵת�͡�InfoQ ��Ϊս�Ժ���ý��֧���˱��η��������ء�
���ż������ϳ��죬һ�廯����������ά����ҵ������ƽ̨�����ѳ�Ϊ��ҵ������ѡ�����������ҵ�Ĵ�����ҵ֮һ��Snowflake �����Զ��ƶ�����һ�廯������ƽ̨�� SaaS ����ҵ��ģʽ��ȫ������Ͽɡ����ڼ�����̬���û���̬���г������IJ����ԣ����ڹ���“�й��� Snowflake”�ĺ���һֱ���ڣ����� Lakehouse ϣ����Ϊ“�й��� Snowflake”��������ҵ�����Զ��ƶ�����һ�廯 SaaS ������������г��Ŀհס�

�����Ƽ���ʼ�� &CEO ��˼�ɱ�ʾ��“���ơ�һ�廯�����ݼܹ��ݽ��ı�Ȼ�����ջݡ����¼����µ��Ե�����ƽ̨�ǵ�����ҵ�Ĺ������������Ƽ���‘�ı����ݵ�ʹ�÷�ʽ’Ϊʹ�����ۼ���ҵ��ר�ҳ�Ա����ʱ�����Ƴ���ȫ�����з������� Lakehouse��������ҵ������ԭ���ͻ���������Ч������ȫ�������õط������ݵļ�ֵ��”
����Lambda �ܹ���Single-Engine ͳһ“���ߡ�ʵʱ�ͽ�������”
�����ݵĿ��ٷ�չ��Դ���� Hadoop Ϊ���ĵĿ�Դ��������ҵ���ڣ�������̬��δ�㹻���죬��ҵ����ѡ����ϲ�ͬ�Ŀ�Դ����Խ�����ƽ̨��ͨ��ʹ�� Lambda �ܹ���

���ǣ���װʽ Lambda �ܹ�һֱ���� �Ĵ�����ؽ�������
��һ����ͬ����������Բ�ͨ�������ϸ߿����ż����Կ�����Ա�����Ѻã�
�ڶ��������������Ԫ���ݣ����������ļ���ʹ洢���ࣻ
������������ܹ����ӣ��������ߵ���ά�ɱ���
���ģ�ȱ������ҵ��仯������ԡ�
��Щ��������ҵ����꣬�ܶ��Ʒ����ҵҲ���Խ����Щ���⡣�������������������ļ���ģ�͡�����������ʽ�Լ��洢ϵͳ��ƾ���ͬ���������ͽ��������ļ���ģ�͡��洢ģ�͡�����ģ�͡���Դģ��Ҳ��ͬ����ˣ���ҵ��Ҫͳһ���ߡ�ʵʱ�ͽ������������Ϊ���ѡ�

�������������·�ʽ��Single-Engine ����ƽ̨ͳһ���������������ּ���ģʽ
�����Ƽ����ϴ�ʼ�˼� CTO ���α�ʾ���������������������ּ�������ļ���ģ�͡�����������ʽ���洢ϵͳ��ơ�����ϵͳ��ơ���Դģ�͵Ⱦ�����ͬ�����Ƕ����Ѹ�����������������ͳһ���ּ���ģʽ����Ҫһ���µļ��㷶ʽ���������‘��������’��
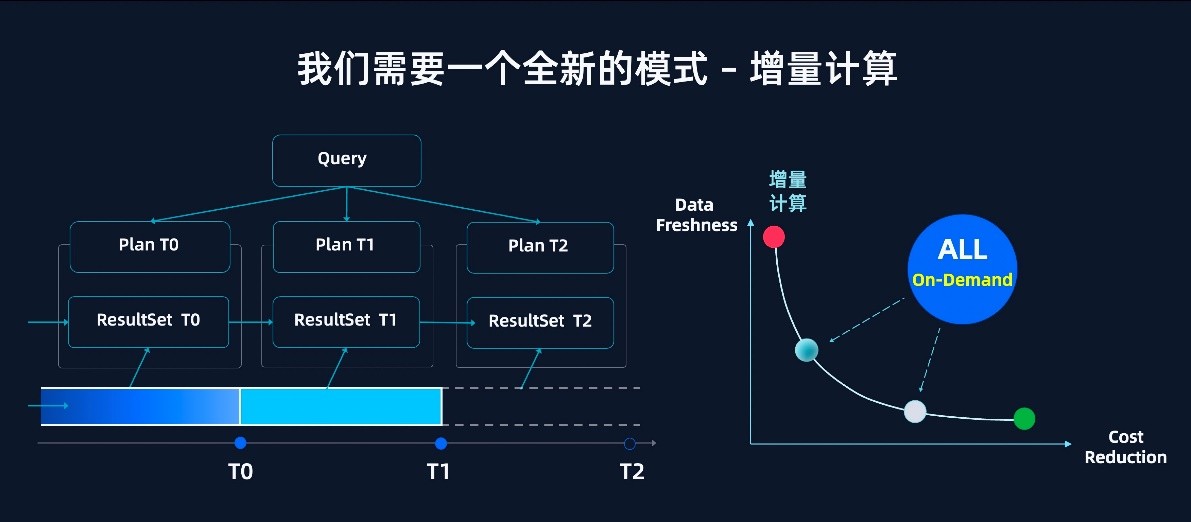
��������ָ���ǽ����м���������������̬��ʵ�����ݵ�һ�μ��㡢�۴�ʹ�ã���ʡ������Դͬʱ�����ṩ��������“����ʱ����”���������������������Ч���ķ���
“���������ʱ��������Ϊ 0������ƽ̨���ṩʵʱ���㣻�����������ʱ����������ƽ̨��ʵ��������������”���ν��͵�����ҵ������Ҫʹ�õ�������ʽ�������Ա�д���������ĸ���ҵ�����������������ݼӹ��Ĵ��������ɹ���ʵʱ����
�·�ʽƽ��“���ݲ���������”��������Ȩ���ظ���ҵ�Լ�
�����Ƽ����ϴ�ʼ�˼� CTO ���α�ʾ��”Single-Engine �ĺ���ʹ��‘��������’���¼��㷶ʽ�����������ʶȡ���ѯ���ܺͳɱ���‘���ݲ���������’��֧�ֶ���ƽ��㣬�����˰�ƽ��Ŀ���Ȩ���ظ���ҵ�Լ���”
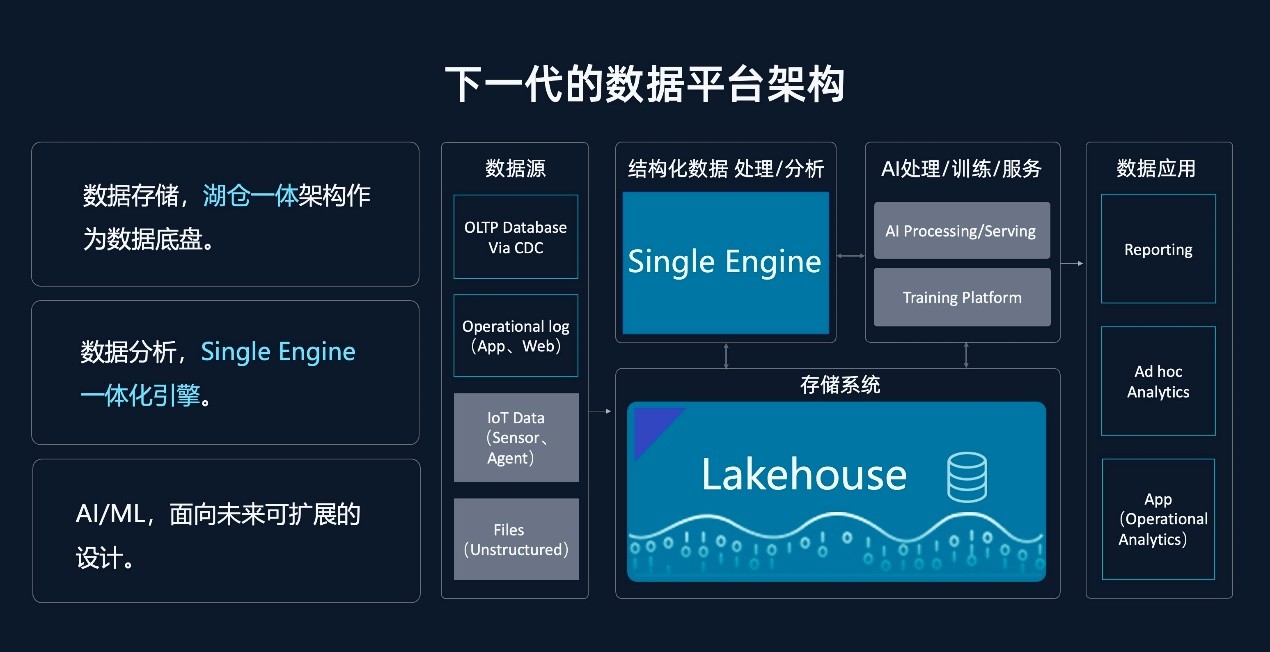
ͬʱ�������� Lakehouse ���ݼܹ��У��ײ�ĺ���ƽ̨����ʵ�������ݺ������ݲֿ���ںϣ�����һ�壩�����еĽṹ�����ǽṹ������ͳһ�洢�ں��ּܹ��У�ֻ��һ�����ݣ�ͬʱΪ��֧���ϲ�����������̬�������� Lakehouse ������ʵ���������洢�������������ݵ���ʵ��Ϊ“�߱������洢������ Lakehouse”��
���� Lakehouse �� Single-Engine ���������Ѿ�չ����Խ�����ܡ�
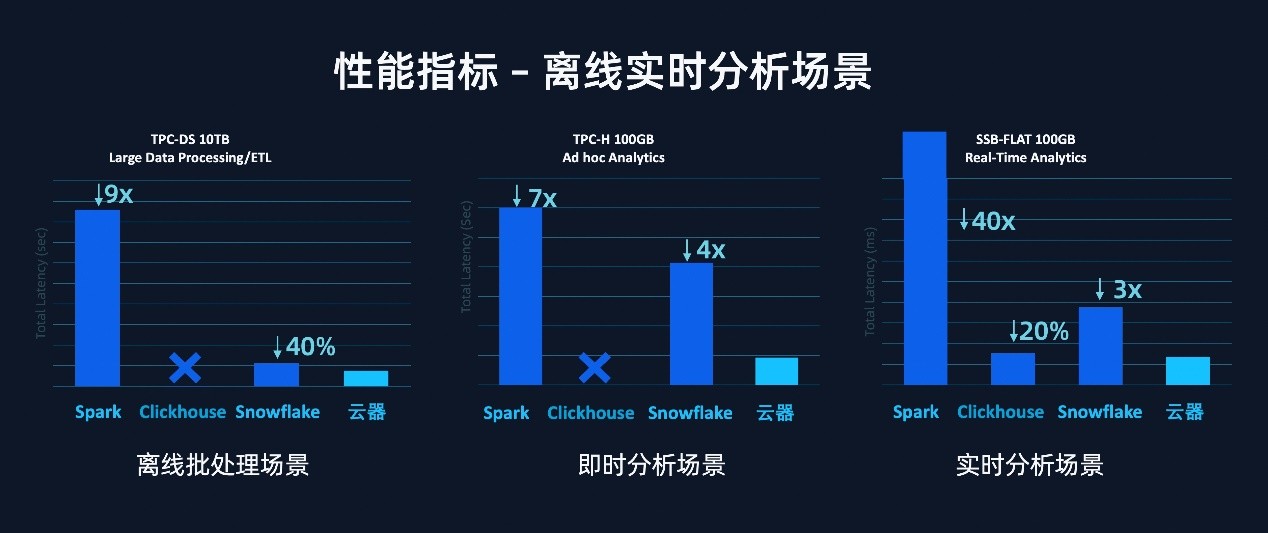
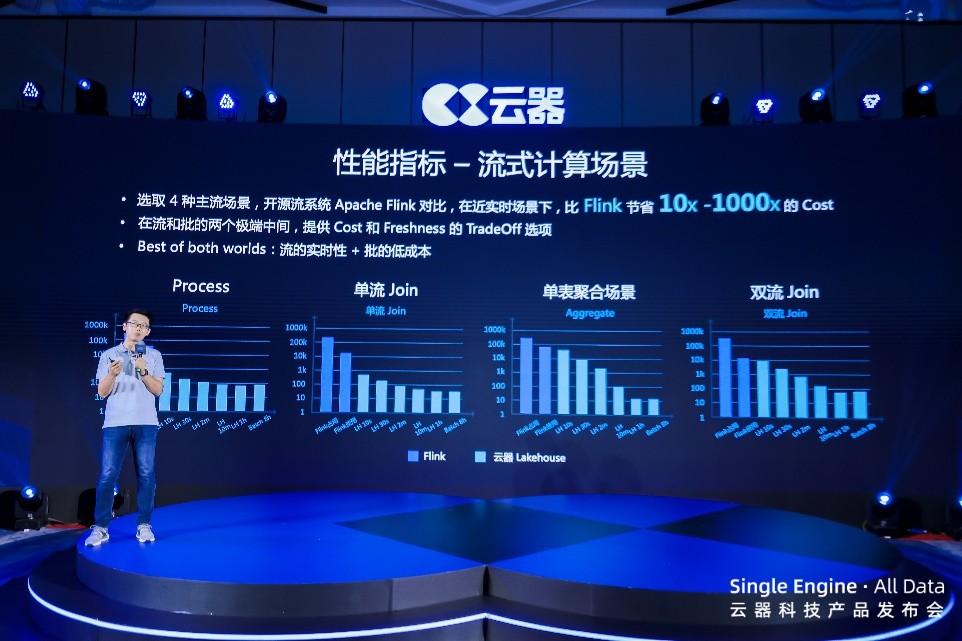
����������ʵʱ���������ϣ����� Lakehouse �ڶ��ֱ� benchmark �ϱ�������Դ����ҵ��Ʒ�� 3-9 ����
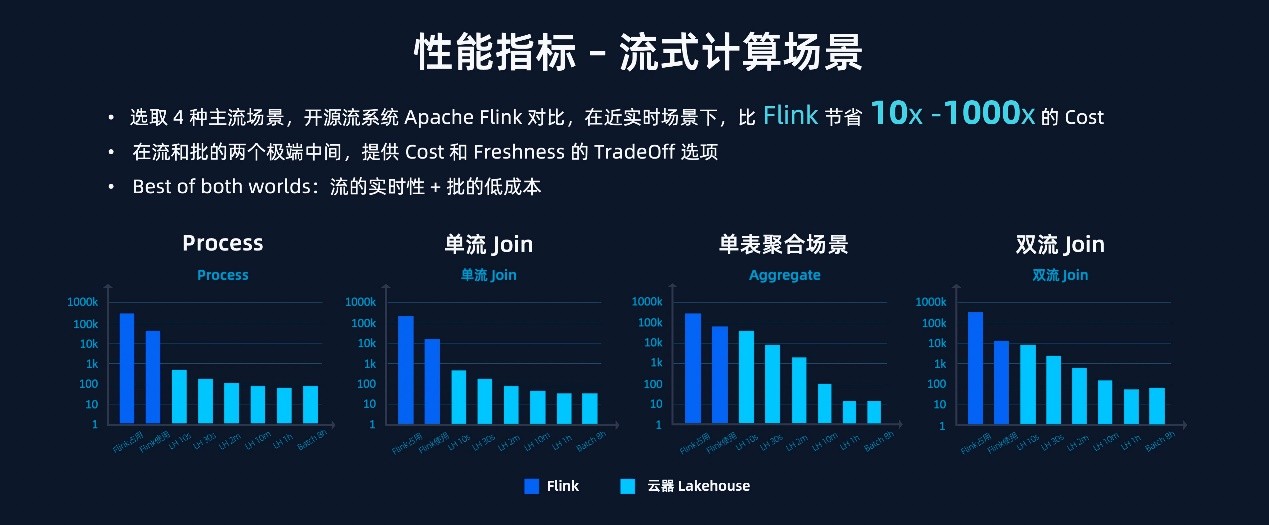
��ʽ���㷽�棬�� Process��Aggregate������ Join ��˫�� Join �������������£����� Lakehouse ��ȿ�Դ��ϵͳ Apache Flink �����˸����ĵ������������ڽ�ʵʱ�����£��� Flink �� 10 ��—1000 ���ijɱ���ʡ��
���ơ�һ�廯������ƽ̨������ҵ��������ʹ�ø���
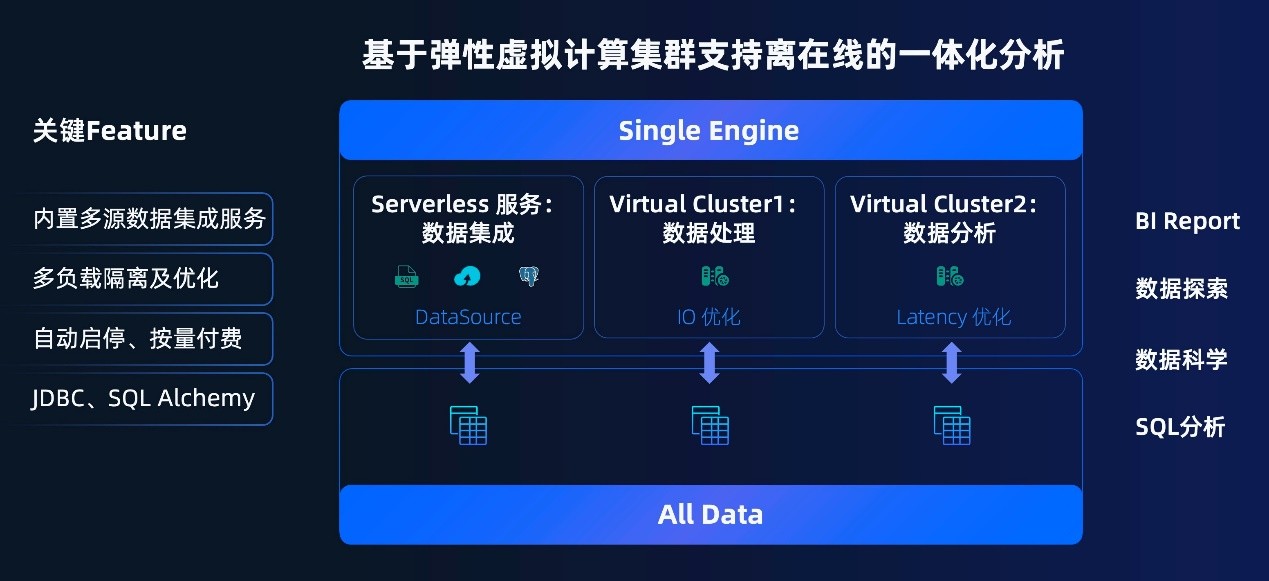
���� Lakehouse �ں���һ��� Single-Engine �Ļ����ϣ����ڵ���������㣨Virtual Cluster��֧�������ߵ�һ�廯����������ʵ�ֿ��伴�á��뼶������Դ���������ѡ�
Single-Engine һ�廯��ƣ�������һ�廯����ƽ̨��“����Ӧ”���ԣ�������ҵ����֧�ָ��ε���ҵ������Ӧ�ã�������ֿ�Դ��ϼ������������������ Spark/Presto/Flink/Clickhouse ��ƽ�淽�����Գ�������ҵ�dz��Ѻá�

�����Ƽ����ϴ�ʼ�˼� CPO ������ʾ��“һ�廯�ǹ�ʶ�ķ�������ѡ�������� Single-Engine �ķ�ʽ������֮�����ڿ��Ը��õذ�����ҵƽ�⣺���ܡ��ɱ����������ʶȡ�ʹ��ƽ̨�ܹ���ʹ�ø���”
һ�廯����ƽ̨��������ҵʵ��BI �� AI ����

�����Ƽ����ϴ�ʼ�˼� CPO ������ʾ��“���ݲ�����ֻ��Ϊ�� BI ������ͬһ�������ܹ�ͬʱ������ BI+AI��ʵ�� BI+AI �������������� Lakehouse ��Ʒ�ij��ġ�”
�Գ��г���Ϊ�������е�����·����������ʷ·����Ϣ���ṹ�������ݣ�+ �����켣�����ݣ�ʵʱ��ṹ�����ݣ�������ɵġ��ڳ����١�̽�����Ϊ�쳣�ĵ�·�ϣ���Ϣ��ȷ�����һ�����֣��������ͨ����ҵ�鱨���ݱ���ʵʱ·��ͼƬ��ͨ�� AI ģ�ͷ�����Щ�ǽṹ�����ݣ���ǿ����·�����ݵ�ȷ�ԡ�
���� Lakehouse �������Ż��� AI �������Ż�������·�ͽ�������ƽ̨ʹ���ż�����ǰ����ҵ�ڴ���һ�����Ե�ʹ�����û���ģ�ͷ���ҵ������Ȼ�dz����ӣ����е��Ż���������Ȼ�д������˹��������Ż��̶�ԶԶ������
��ˣ��� AI �Ѿ���Ϊ��������һ�ȹ���Ľ��죬�����Ƽ�̽���ƶ�һ�� AI4D��AI for Data�����·���ͨ��ƽ̨����ѧϰ���ݺ��ص����ԣ��������㷨�� AI ���Զ������������������ҵ��������ÿһλ��ҵ��Ա���ܵ��ż�ʹ������ƽ̨��AI4D ��AI for Data��ָ���ǻ��� Learning based ������ AI �㷨��ƽ̨�Ż�����

������Ϊ��“����ƽ̨�ܷ�֧�ֺ� AI�������ú� AI���Ѿ���Ϊ������һ������ƽ̨���±���”
������� Lakehouse AI4D �Ѿ�ʵ�֣����ƻ���ר�Ҿ�����Ż����������ݷ���������ѧϰ�� AI �㷨�Ż�����ƽ̨�������ݽ�ģ�����ϣ�ͨ�� AI“ѧϰ”���� pipeline ��һ��ʱ�����ʷ��ѯ�����ʵ���Զ� MV ��ȡ���Զ�Ԥ���㣬�Զ����� / �ɱ���ƽ�⡣
����ʹ�� AI4D �������ڱ����ݼ����Եõ��� ~16% ������Դ��ʡ����ͨ�� MV תԤ���㣬��ѯʱ���� 30%~ 4 �����������档
��ʵ�ʿͻ������ݼ��У����Դﵽ�� 40% ����Դ���Ľ��ͺ�Ԥ�� 3 ���IJ�ѯ����������
����Lakehouse ʹ������

���������ܼ�ŷ��ϱ�ʾ��“��Ϊһ������ԭ�� SaaS ��ҵ�����ܻ��������Ϊʲô���ǻ�ѡ�������������ʵ���ϣ���Ϊһ�ҳ�����ҵ��������Ҫ����ҵ��Ŀ��������ʱ�������ݼܹ��������� Lakehouse һ�廯����ƽ̨�������Dz��ظ��ݲ�ͬҵ������ȶԡ����϶�Ҽ�����Ʒ���ܴ�̶��Ͻ�ʡ�����ǵľ����ͳɱ������⣬�����ŶӸ߶���Ӧ����ҵ������������������Ա��ȫͶ�뵽ҵ���С�”

��Ϊһ�� SaaS ��ҵ��ǰ�˼��� & �¼����ܼ࣬���ڰ��ʾ��“���� Lakehouse �� AI4D �������������Զ�������ʷ�����еĴ�����ͬ�ļ����Ӽ��Ż��ɹ��õ� mv������֮���������ֱ��ͨ�� mv ����ȡ�������������ÿһ�� query������ʵ���� 2.1 �� CPU ���ijɱ��Ľ��ͺ� 5.9 ����ƽ�������ӳٵ����̣�����ȼ����˼�����̲������˳ɱ����ģ���������ǹ�˾����ҵ����ת��Ч�ʡ�”
Single Engine · All Data
“�ڹ�����Խ���һ��ѡ���Խ����ͻ���Ҫ��ض�������ķ�ʽ��������������Ʒ������Ĺ��ɡ���������Ҫ Single Engine · All Data���Ѹ��������������Ѽ������ͻ���”�����Ƽ���ʼ�� &CEO ��˼��ǿ����
�����������˼���������� Lakehouse ��Ʒ��������ͨ����ʽ��������ӭ��ҵǰ�������Ƽ������� https://www.yunqi.tech���ύʹ�����롣
|