「比大更大」(Bigger than bigger)当年苹果的一句广告词,用来形容现在 AI 领域最热的大语言模型,看起来也没什么不对。
从十亿、百亿再到千亿,大模型的参数走向逐渐狂野,相应的,用来训练 AI 的数据量,也以指数级暴增。
以 OpenAI 的 GPT 为例,从 GPT-1 到 GPT-3,其训练数据集就从 4.5GB 指数级增长到了 570GB。
不久前的 Databricks 举办的 Data+AI 大会上,a16z 创始人 Marc Andreessen 认为,二十几年来互联网积累的海量数据,是这一次新的 AI 浪潮兴起的重要原因,因为前者为后者提供了可用来训练的数据。
但是,即便网民们在网上留下了大量有用或者没用的数据,对于 AI 训练来说,这些数据,可能要见底了。
人工智能研究和预测组织 Epoch 发表的一篇论文里预测,高质量的文本数据会在 2023-2027 年之间消耗殆尽。
尽管研究团队也承认,分析方法存在严重的局限,模型的不准确性很高,但是很难否认,AI 消耗数据集的速度是恐怖的。
低质量文本、高质量文本和图像的机器学习数据消耗和数据生产趋势|EpochAI
当「人类」数据用完,AI 训练不可避免地,将会使用 AI 自己生产的内容。不过,这样的「内循环」,却会产生很大挑战。
不久前,来自剑桥大学、牛津大学、多伦多大学等高校的研究人员发表论文指出,用 AI 生成的内容作为训练 AI,会导致新模型的崩溃。
所以,AI 训练用「生成数据」会带来崩溃的原因是什么?还有救吗?
01
AI「近亲繁殖」的后果
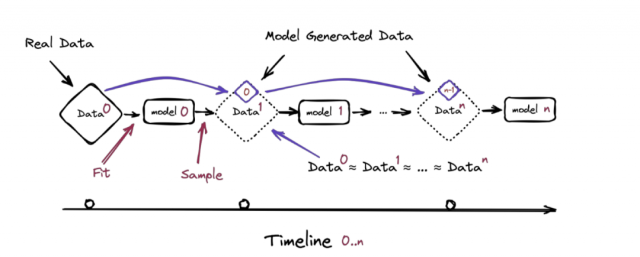
在这篇名为《递归的诅咒:用生成数据训练会使模型遗忘》的论文中,研究人员指出,「模型崩溃」是一个几代模型的退化过程。
前一代模型生成的数据,会污染下一代模型,经历几代模型的「传承」,它们就会错误地感知世界。
模型迭代示意图|arxiv
模型崩溃分为两步:
在早期模型崩溃中,模型会开始失去原始数据的分布信息,也就是「干净的人类数据」;
在晚期,模型会把上几代模型对原始分布信息的「错误认知」纠缠到一起,从而曲解现实。
研究人员首先从头训练了小样本模型 GMM(高斯混合模型)和 VAE(变量自动编码器)。以 GMM 为例,下图最左是原始数据的正态分布。
可以看到,模型一开始对数据的拟合非常好。到第 50 次迭代时,基础数据分布开始被错误感知。当迭代来到 2000 次时,模型已经收敛到一个很小的点,这意味着模型开始稳定输出错误答案。
GMM 在迭代 0、50、100、150、200、350、2000 时拟合数据的例子|arxiv
为了验证预训练对实验结果的影响,研究人员又在 Meta 开发的 1.25 亿参数的 LLM(大语言模型)OPT-125m 上进行了实验,数据集来自维基百科的 wikitext2。
和 GMM、VAE 这类小模型不同,LLM 从头训练的成本非常高,所以它们都是经过预训练的。实验结果如下:
输入:根据 Poyntz Wright 的说法,在 1360 年之前有些活动通常由一位主要石匠和一小队流动的石匠完成,辅以当地教区劳工。但其他作者则否认了这种模式,相反提出主建筑师借鉴英国垂直式风格设计了教区教堂的尖塔。
输出:
第 0 代:复兴建筑,例如伦敦的圣约翰大教堂。现存最早的垂直复兴建筑可以追溯到 18@-@ 世纪的根西岛圣母教堂,该教堂建于 19 世纪末。有两种类型的垂直式教堂:那些
第 1 代:建筑,如罗马的圣彼得大教堂或布宜诺斯艾利斯的圣彼得大教堂。没有证据表明这些建筑 是在教皇英诺森三世统治时期建造的,但有可能是在他的继任者英诺森教皇统治时期建造的。
第 7 代:英国的建筑。在接受《纽约时报》采访时,赖特说:"我不认为我能够做我想做的事情有什么问题。它只是对我不起作用。"他补充说:"我不知道你是否可以称之为有趣、
第 9 代:建筑。除了成为全球黑 @-@ 尾巴大野兔、白 @-@ 尾巴大野兔、蓝 @-@ 尾巴大野 兔、红 @-@ 尾巴大野兔、黄 @-的最大栖息地之一
可以看到,到第 9 代模型时,输出的内容已经完全不知所云。
论文的作者之一 Ilia Shumailov 说,随着时间的推移,人工智能生成的数据中的错误不断累积,主要的模型在接受这些数据的训练后,会对现实产生更加扭曲的看法。
02
为什么会模型崩溃?
「模型崩溃」产生的最主要原因,还是因为 AI 并非真正的智能,它展现出的近似「智能」的能力背后,其实是基于大量数据的统计学方法。
基本上,所有无监督机器学习算法都遵循一条简单的模式:给定一系列数据,训练出一个能描述这些数据规律的模型。
这个过程中,训练集里更大概率出现的数据就更容易被模型重视,小概率出现的数据就会被模型低估。
举个例子,假设我们需要记录 100 次骰子的投掷结果,来计算每个面出现的概率。理论上,每个面出现的概率是一样的。在现实生活中,由于样本量较小,可能 3、4 出现的情况比较多。但对于模型而言,它学习到的数据就是 3、4 出现的概率更高,因而会倾向于生成更多的 3 和 4 的结果。
「模型崩溃」示意图|arxiv
另一个次要原因是函数近似误差。也很好理解,因为真实函数往往很复杂,实际运用中,经常使用简化的函数来近似真实函数,这就导致了误差。
03
真没招了吗?
杞人忧天!
所以,在人类数据越来越少的情况下,AI 训练真的没机会了吗?
并不是,用于训练 AI 数据枯竭的问题,还有方法能解决:
数据「隔离」
随着 AI 越来越强大,已经有越来越多的人开始使用 AI 辅助自己工作,互联网上的 AIGC 爆炸式增长,「干净的人类数据集」可能会越来越难以找到。
谷歌深度学习研究部门谷歌大脑 Google Brain 的高级研究科学家 Daphne Ippolito 就表示,在未来,要找到高质量、有保证的无人工智能训练数据将变得越来越棘手。
这就好比是一个患有高危遗传病的人类始祖,但是又拥有极其强大的繁殖能力。在短时间内他就把子孙繁衍到了地球每一个角落。然后在某一时刻,遗传病爆发,人类全体灭绝。
为了解决「模型崩溃」,研究团队提出的一种方法是「先行者优势」,也就是保留对干净的人工生成数据源的访问,将 AIGC 与之分隔开来。
同时,这需要很多社区和公司联合起来,共同保持人类数据不受 AIGC 污染。
不过,人类数据的稀缺意味着这其中有利可图,已经有一些公司行动起来了。Reddit 就表示将大幅提高访问其 API 的费用。该公司的管理人员表示,这些变化 (在一定程度上) 是对人工智能公司窃取其数据的回应。Reddit 创始人兼首席执行官 Steve Huffman 告诉《纽约时报》:「Reddit 的数据库真的很有价值。」「但我们不需要把所有这些价值都免费提供给一些全球最大的公司。」
合成数据
同时,专业基于 AI 生成的数据,早已有效用于 AI 的训练。在一些从业者看来,现在担心 AI 生成的数据会导致模型崩溃,多少有点「标题党」。
光轮智能创始人谢晨告诉极客公园,国外论文提到的,用 AI 生成数据训练 AI 模型导致崩溃,实验方法比较偏颇。即便是人类数据,也有能用和不能用之分,而论文提到的实验,则是不加分辨地直接用来训练,而并非有针对性的经过质检、效用性判定后作为训练数据,显然有可能会造成模型崩溃。
谢晨透露,其实 OpenAI 的 GPT-4,就采用了大量前一代模型 GPT-3.5 生产的数据来进行训练。Sam Altman 也在近期的采访中表达,合成数据是解决大模型数据短缺的有效方法。而其中的关键在于,有一整套体系来区分 AI 生成的数据中,哪些可用,哪些不可用,并不断根据训练后模型的效果进行反馈——这是 OpenAI 能笑傲 AI 江湖的绝招之一,这家公司并不只是融的钱多,买的算力多这么简单而已。
在 AI 行业内,使用合成数据来进行模型训练,早已经成为一个尚未为外人所知的共识。
曾经在英伟达、Cruise、和蔚来等公司负责自动驾驶仿真的谢晨认为,以目前各种大模型训练的数据量来看,未来 2-3 年,人类数据确实有可能「枯竭」,但是基于专业化体系和方法,AI 生成的合成数据,会成为用之不竭的有效数据来源。并且使用场景并不局限于文字和图片,像自动驾驶、机器人等行业需要的合成数据量,将远远大于文本的数据量。
AI 三要素,数据、算力、算法,数据来源有着落了,算法大模型在不断进化,唯一剩下的算力压力,相信英伟达创始人黄仁勋是可以顺利解决的。