喜马拉雅作者:李超、陶云、许晨昱、胡文俊、张争光、张玉静、赵云鹏、张猛
1.业务介绍
喜马拉雅app的主要推荐场景有:每日必听、今日热点、私人FM、猜你喜欢、VIP信息流、发现页推荐等。
喜马拉雅AI云,是面向公司人员提供的一套从数据、特征、模型到服务的全流程一站式算法工具平台。
其特点在于提供了数据、画像、特征、模型、组件、应用等多个资源管理能力,通过可视化建模界面以及算法组件化能力,支持用户通过拖拽链接方式生成完整的数据->特征->样本->模型->服务的完整工作流程。平台还支持丰富的特征、模型参数化定制能力,使得用户不用频繁修改代码仅在UI界面填写参数即完成调参、任务多场景支持等,极大的降低了用户的使用成本,提升了公司整体算法开发效率。
平台上一个常见的深度模型训练DAG如下图所示:
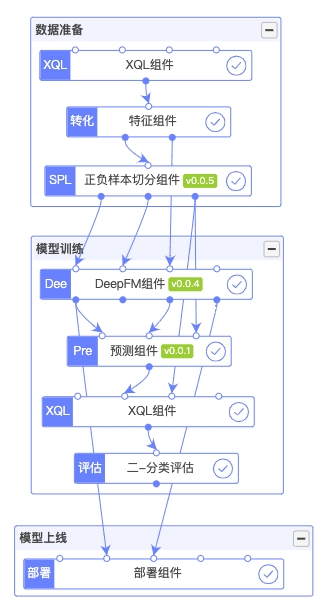
目前平台支持了喜马拉雅多个app的推荐、广告、搜索推荐等主流业务场景,以及画像产出、数据分析、BI数据生成等多个定制化开发场景。
2.合作背景
随着公司算法能力的迅速提升以及搜广推业务的不断增长,平台推荐技术栈快速从机器学习过渡到深度学习,并对样本量级、特征维度、模型复杂度有着不断增长的需求。平台主要的深度技术框架是通过spark实现数据处理和parquet形式保存,通过k8s实现gpu资源调度,使用tensorflow实现模型训练。在具体实现过程中,有2类主要的痛点:
2.1 高维稀疏特征支持
hash冲突问题:一般对高维ID的简化操作就是hash。我们测试发现特定特征在hash到千万级别空间后冲突率能达到20%以上,要降低到5%以内需要扩充到五倍以上空间,失去了压缩的意义。我们自研实现了一种多重hash方案,通过将高维id映射到3个万级空间,相同场景下冲突率降低到0.2‰,参数量降低95%。但上线后发现也有缺陷,即对长序列id特征列表,会扩充到原有3倍长度,显著降低了模型的推理性能。特征入场/退场/变长:这些均是对高维ID特征的基础要求。通过合理的配置这些参数,可以实现高维稀疏大模型部署模型大小的缩减以及模型指标的稳定。使得支持十亿特征维度以上模型的训练和部署成为可能。
2.2 模型快速迭代
模型分钟级别更新:当前我司主要业务的模型更新一般是天级别。在特定需要高频响应的业务中,需要提升到小时级或者分钟级。其间隔主要受限于数据回流、数据处理、模型训练,以及模型上传的总耗时。如果仅是将上述天级的流程加快(kafka数据流),最理想情况也就能做到小时级,无法做到更快迭代。同时,由于每次部署均是一个全量模型,模型增大后,线上服务加载模型时的不可用时间也会显著增长。
综上所述,为解决上述问题,以及为未来发展预留一定的技术可扩展空间,我们计划采用业内主流开源技术+落地实施方案。在考察阿里的DeepRec、腾讯的TFRA/DynamicEmbedding,以及Nivida的HugeCTR框架后,我们决定采用阿里提供的开源DeepRec。
3.DeepRec功能落地
3.1 高维稀疏特征
在搜索、推荐和广告领域,特征往往具有高维稀疏的特点,原生Tensorflow对稀疏参数支持是通过在图中创建一个固定shape的variable,然后把稀疏特征通过hash+mod的方式mapping到Variable中来实现的。这会带来4个突出的问题:第一是稀疏特征的冲突,比如不同的稀疏ID mapping到同一个行内,第二是设置shape 太大会导致内存的空洞,第三是static 的shape,当用户一旦确定该shape在后续训练都不可以修改,在在线学习的场景中稀疏特征量的变化也是合理的场景,第四点是低效的IO,在稀疏模型导出checkpoint的时候会全量的导出。
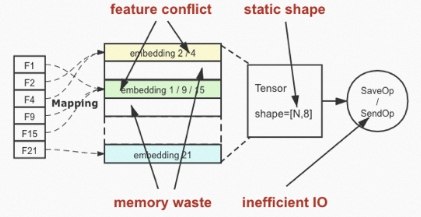
在DeepRec中,Embedding Variable使用动态的类似HashMap数据结构存储稀疏参数,保证了稀疏特征数目是可以弹性伸缩,在保证特征不冲突的情况下,也一定程度的节约了内存资源。围绕这个功能,Embedding Variable针对业务场景,支持了特征的准入(特征入场),特征的淘汰(特征退场),以及利用不同介质混合存储Embedding Variable提高特征规模,降低存储成本等功能。
3.1.1 高维稀疏特征ID支持
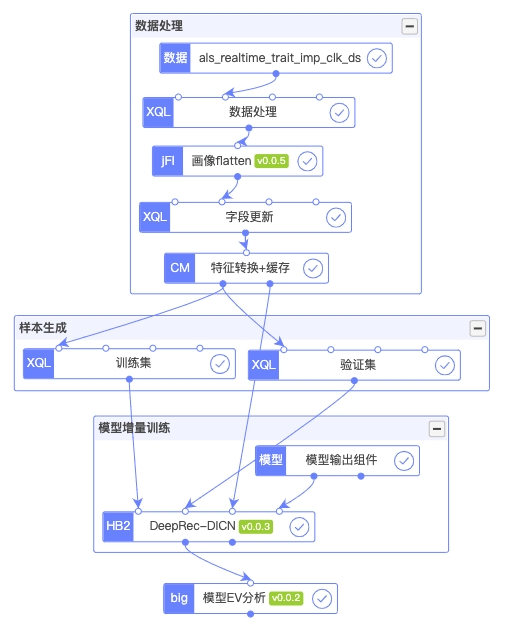
高维id特征如用户id、商品id等一直是深度模型特征的主要处理对象。模型引入这类特征、以及其延伸的交叉特征后,特征维度可以轻易超出biillon级别。常见的hash解决方案往往又会陷入冲突率和模型参数的平衡问题中。通过使用DeepRec的EmbeddingVariable,以额外"EV"的op管理模型训练中每个特征id的更新使用情况,并辅以针对每个特征的参数设置,可以有效的平衡高维稀疏id以及最终模型的参数量大小。同时,是否开启"EV"也可以针对每个特征进行配置,关闭后就是原生的tensorflow实现。用户可以针对是否高维id,自行判断开启或关闭该选项,使用非常灵活。以下是我们基于DeepRec高维稀疏特征能力,在我们AI云平台落地后的用户使用界面图示:
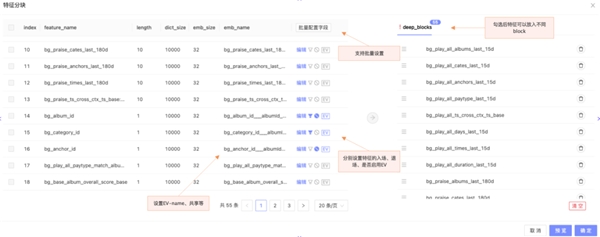
3.1.2 特征入场、退场
我们在实践中选择了基于Counter的特征准入以及基于global step的特征淘汰功能,经过严格测试,功能符合预期。在实际的使用过程中,我们的经验是:全量特征可以默认关闭"EV"选项,只针对高维稀疏特征开启;可以先开启准入选项,设置一个比较大的值,训练模型。然后基于EV分析工具查看具体情况做灵活调整。最终模型开始长周期滚动更新时,按照需求开启退场选项。其中需要注意的是,入场和退场的次数设置,前者是这个id的更新频次、后者是总训练的step数(batchsize),有较大区别。还有就是验证集的数据也会参与EV记录。
3.1.3 未入场特征
DeepRec对待未入场和入场后的特征,其初始值逻辑是一样的。即在训练启动时,初始化一个较小的embedding-table矩阵(类似标准的embedding初始化),上述id进入后,不做初始化而在该矩阵中查取(随机)。未入场前,不参与梯度更新,入场后参与更新。线上serving时,统一返回默认值(0)。DeepRec支持了未入场特征与入场特征初始化值可灵活配置的功能。我们在实际使用中,对于上述的未入场的特征,均统一设置初始化默认值为0,对齐了训练和推理,也便于后续进行mask操作。对于入场后的特征沿用之前的参数初始化方式。针对上述入场、退场,以及未入场的特征的处理逻辑,我们做了以下示意图帮助用户理解:
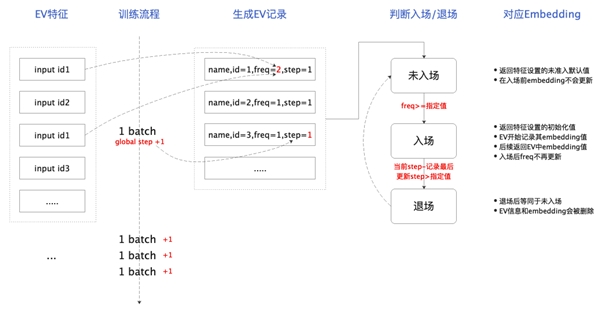
3.1.4 EV分析
EV分析是模型训练调参中的一个重要工具。DeepRec提供了分析函数,我们将此做成一个功能组件供用户使用。以下是我们模型增量更新时的一个完整流程图,模型EV分析组件可以在每次训练结束后进行,提供特征名称、id值、向量、更新频次、最近更新step等具体细节,帮助用户分析模型和样本情况,从而进行相关参数配置,或者调整上游样本数据:
3.1.5 特征多级存储
DeepRec的特征多级存储功能,主要解决训练时模型参数量过大,pod内存无法承载的情况,这个正是我们目前碰到的主要问题。用户可以配置保存embedding参数要使用的存储(HBM,DRAM以及SSD),之后多级存储会基于一定的cache策略自动地选择将高频被访问到的特征保存到小容量的高速存储中,其他特征则放置到大容量的低速存储。结合推荐场景中特征访问的倾斜性(20%的特征访问数占总访问数的80%以上),可以在训练效率不受显著影响的情况下有效地减少模型的内存使用量,降低模型训练的成本。目前我们正在和阿里云合作落地该功能。
3.2 实时训练
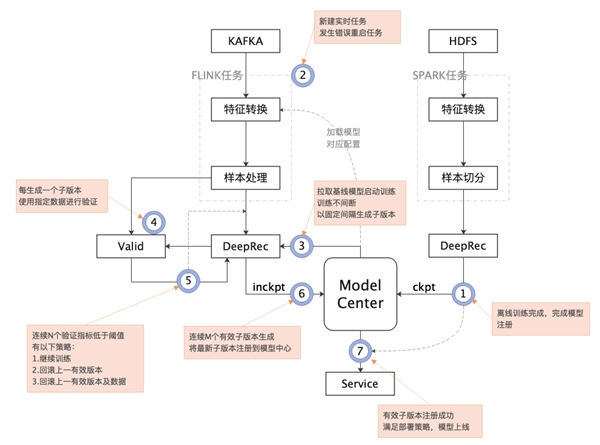
DeepRec的另一个主要功能是提供了增量模型的导出功能。即仅将增量训练的变化的参数导出成ckpt,线上仅新加载这部分文件。这样能将模型更新所需的文件大小从上百G降低到几KB大小。使用这个功能,可以解决模型部署上线的模型传输和模型加载耗时,使得线上分钟级别的模型更新成为可能。我们重新优化了流批一体的训练流程,完成了基于增量模型的全流程验证。并在业务场景实现了10分钟级别的模型迭代测试。以下是我们基于DeepRec流批一体模型训练的流程示意图:
3.3 线上推理
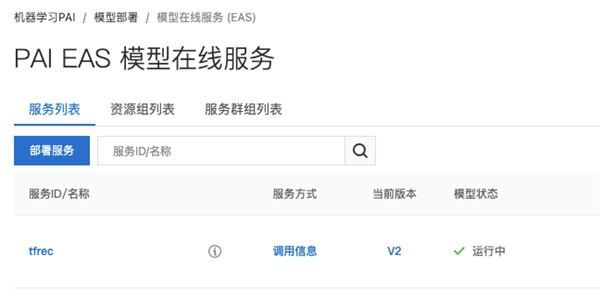
processor:DeepRec官网已经提供了对应的libserving_processor.so文件,也可以按照用户使用的版本自行编译,支持模型自动识别、增量更新、SessionGroup等功能。满足业务需要。PAI-EAS:阿里云还提供了PAI-EAS在线推理服务。用户只需要将模型文件部署到oss上,可以直接使用其在线推理功能。该服务还提供了常见的压测、扩缩容、线上debug、性能监控以及日志等功能,可以满足一站式部署需要。我们对此进行了测试,在专线开通的前提下,rt等性能指标符合上线要求。
4.总体收益
模型训练:整体流程改造完毕之后,我们在单worker训练中GPU平均利用率提升到40%以上(视具体模型),训练环节整体耗时减少50%以上。模型上线收益:我们目前在一个主流推荐场景中完成了全量上线。在对齐特征和样本情况下,在主要指标ctr、ptr等就有2%~3%+的正向收益,rt、超时率等推理指标基本持平。在引入简单的高维id及交叉特征后,其正向收益也有2%~3%+。其他主流业务场景模型也在逐步切换中。
5.未来规划
我们对后续的一些功能也在进行探索,以便更好的支撑业务需求:
SessionGroup:DeepRec提供的线推理能力。在模型达到一定大小后,线上推理需要相应的内存。以实体物理机进行超大内存划分,往往会造成对应的CPU资源无法得到重复利用。该功能即在同一pod上,模型内存共享的情况下,提供并发推理能力。使得单节点的资源利用率,以及支撑QPS上限得到显著提升。我们已经开展对该功能的测试。模型压缩和量化:目前模型训练过程以及模型导出的文件中,均包含相应的EV信息。在高维id场景中会占用很大一部分空间。在线上推理阶段可以舍弃该部分,加快模型传输及加载,以及降低内存使用。同时,基于DeepRec生成的模型量化裁剪,我们也在研究中。多模型推理、GPU推理等:基于DeepRec提供的CUDA Multi-Stream和CUDA Graph的能力,可以极大的提升Inference场景下GPU的使用效率,基于GPU进行模型的推理可以进一步提升对复杂模型的推理的效率以及降低推理的成本。
6.感谢
感谢DeepRec社区在合作共建阶段提供的技术支持,其技术精湛、服务热情、响应快速。帮助我们快速落地大模型训练和推理能力,带来了业务指标和后续算法优化空间的显著提升。特此感谢!
|