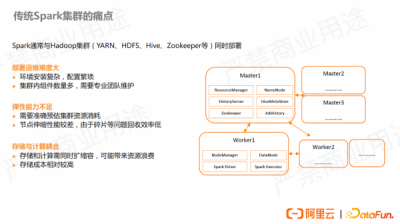
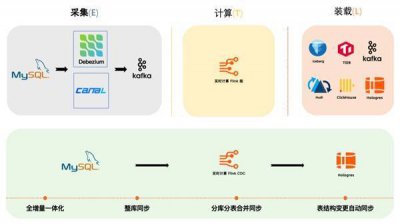
Spark 集群通常与Hadoop集群比如YARN、HDFS、ZooKeeper等同时部署。
——范佚伦(子灼)
一、Spark与云原生结合的优势
Spark 集群通常与Hadoop集群比如YARN、HDFS、ZooKeeper等同时部署。此类全家桶式的部署方式组件较丰富,因此安装、部署、运维都比较复杂,需要较大的运维和人力成本。
另外,需要准确预估集群资源的消耗并提前准备,弹性扩容能力较差。该模式下为了保证数据的稳定性,既要部署 HDFS 的 DataNode,也要部署 YARN 的 NodeManager ,存储节点需要扩容时,意味着 CPU 和内存也要扩容,会导致资源浪费。
而如果将 Spark 部署在云上,充分利用云原生的特点,则可以完美规避上述痛点。

不同组织对云原生有不同的定义。云原生代表通过技术可以充分利用云计算资源和服务优势,高效地在云上部署和运行各种应用程序。在云上部署意味着可以利用云上的海量资源,且能够按需使用。 Spark 作业可以结合以上特点实现作业成本和效率的优化。
云原生的最大特点是秒级弹性以及更细粒度的按量付费。同时,实现了更好的弹性,也意味着环境部署更敏捷,比如运用容器镜像技术,使Spark 运行环境和集群不再绑定,避免依赖冲突的问题,可以轻松运行多版本Spark。
此外,云上提供了全托管的服务替代Spark原先依赖的组件,比如用OSS替代HDFS,用DLF元数据替代Hive Metastore,减少了组件数量和部署复杂度,降低了运维成本。
二、Spark on k8s原理介绍

Spark 获取运行时资源主要通过 Cluster Manager 对象。目前 Spark 官方支持以下四种部署模式:
Standalone:不依赖外部调度器,可独立部署。但一般用于测试,很少在实际生产环境中使用。
Hadoop YARN:业界最常见的部署模式,生态比较丰富。
Apache Mesos:随着k8s兴起,此模式使用者已经较少。
Kubernetes:直接使用k8s调度和申请Spark作业资源。随着云原生趋势,该模式拥有越来越多的使用者。

Spark on K8s的部署架构通常有两种方式。
方式一:使用原生spark-submit。需要在 client 端安装 Spark 环境并配置kubectl用于连接 k8s 集群。提交命令时需要额外指定k8s 的 master 地址和镜像地址。而后Spark 会自动将作业提交到 k8s 集群里,k8s集群内无需提前配置和安装任何组件即可运行。

方式二:使用spark-on-k8s-operator。它是 Google 的开源项目,client段通过kubectl提交yaml来提交作业,也是kubernetes官方推荐的部署复杂应用的模式。该方式是spark-submit 官方方式的一种封装,但它更符合用户的习惯。
除此之外, operator 也实现了作业管理能力的增强,比如可以做定时调度、作业管理、监控、pod增强等,但需要在 k8s 集群里提前安装常驻 operator。

spark-submit 方式对老用户比较友好,迁移难度低,可运行交互式作业。 spark-on-k8s-operator进行了功能的完善,可以自动创建 service、 ingress ,可以自动清理残留的pod、config map 等,支持重试。
Spark2.3正式支持 native on k8s 之前,有人尝试过在 k8s 上用 standalone 或 YARN 模式运行,缺点较多。 Spark3.0后才真正得到完善了 native on k8s。Spark 3.1 正式发布时,将 spark on k8s 做了正式 GA。实际运行中,推荐使用Spark3,它支持了DynamicAlloction,支持自定义podTemplate ,灵活性也得到了很大提升。

最近的Spark 3.3发布了两个重要特性:
①Executor Rolling in Kubernetes environment。
该特性主要针对Spark 作业运行时的慢 executor会产生长尾 task,导致拖慢作业速度,流作业里尤为为严重。慢 executor的产生可能因为机器节点、网络环境、磁盘环境有问题,也有可能是潜在的内存泄露等 bug 。
为了解决该问题,Spark3.3提供了滚动刷新的方式,可以设置刷新频率和刷策略。比如可以结合最近的统计对慢 Executor 做重启,实现 Executor 定期重新拉起,避免拖慢后面的作业。
而重启 SQL 对作业可能产生影响,因此需要结合 Spark 3 提供的另一特性 decommission (优雅下线),以保证 Executor 能够重启,且不会带来 stage 重算等作业的干扰。
②Support Customized Kubernetes Schedule。
k8s 默认调度器对大数据批处理不够友好,功能上存在较多欠缺。而有部分第三方的调度器提供了增强的能力,对大数据提供了较好的支持。为了能够更好地对接这些第三方 k8s 调度器,Spark社区提供了扩展接口和内置的实现类,用户可以方便地通过一些 Spark conf即可与第三方调度器实现对接,能够大幅提升用户体验。
三、Spark on K8s在阿里云EMR的实践
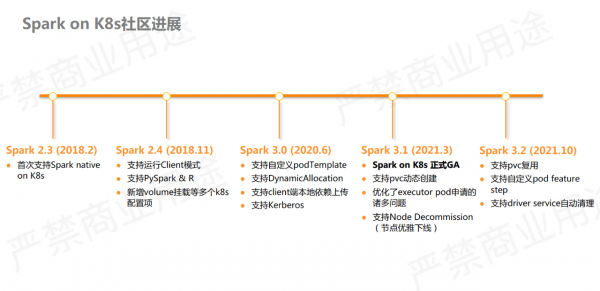
阿里云的公共云上有一款 EMR Spark on ACK 产品。ACK是阿里云容器服务kubernetes版,可以理解为 k8s 集群。Spark on ACK 提供了一套半托管的大数据平台,帮助用户在自己的 k8s 集群里部署好 Spark 运行的环境,并提供了一些功能优化,以及控制台管控等能力。
用户首先需要有自己的 ACK 集群,EMR会在集群里面创建 Spark 作业的 namespace 并安装组件,组件包括 Spark operator, historyserver等。Spark 作业的pod也会在该 namespace 下运行,可以利用自己的 ACK 节点资源,也可以利用云上的弹性实例ECI实现按量付费。
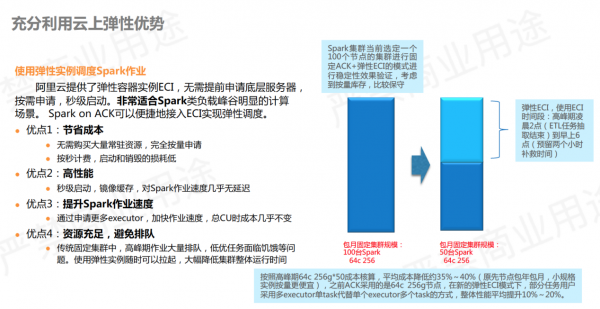
ECI是阿里云提供的弹性容器实例。比如申请一个2核 8g 的 pod,不再需要占用自己机器节点的资源,而是完全利用云上的资源创建 pod ,可以做到秒级拉起,按秒付费。
通常,Spark 做批处理任务的峰谷较明显,因此它非常适合利用ECI极致的弹性。另外,ECI提供了抢占式实例有一小时保护期,可以大幅节省成本,拥有极高的性价比。

Spark shuffle在k8s环境下的运行主要有两个挑战:
①Spark Shuffle对本地存储的依赖。
Spark 作业的 shuffle数据需要落盘,很多大作业 shuffle数据量很大,可达tb级别。在传统Hadoop集群里,节点都会配置比较大的数据盘和 HDFS 同时使用,因此很少出现磁盘不够的情况。但 k8s 环境需要和在线服务做混部, k8s 的很多机型没有本地盘,导致作业很难能利用上资源。如果使用 ECI弹性实例跑 Spark,但此类实例也没有比较大的数据盘,只有少量的系统盘,挂载云盘又会产生性能损失,并且难以评估需要挂载的云盘大小。
②不完美的Dynamic Allocation。
Spark2不支持无ESS的Dynamic Allocation,而Spark3支持无ESS的Dynamic Allocation,但这个功能Executor无法及时回收,会造成资源浪费。
③Spark Shuffle本身的不足。
Shuffle期间会按照数据所属 Reducer 排序,然后合并成文件。排序的过程可能会触发外排,造成磁盘写放大的性能问题。另外,Reducer 并发拉取 mapper 端数据, mapper 端随机读也会影响性能。Shuffle 数据一旦丢失则会引发stage 重算,在 k8s 环境里可能会遭遇节点驱逐、spot 实例回收等问题。
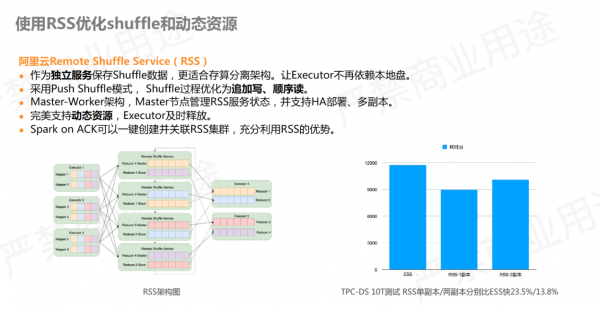
针对上述问题,阿里云提供了Remote Shuffle Service (RSS)服务,目前已经在 github 开源。原先的Spark shuffle 数据保存在 Executor 本地磁盘,使用 RSS 后 shuffle 数据交给 RSS 管理,使本地不再需要占用很大的磁盘空间。该模式已经是业内比较流行的共识。
RSS不仅仅带来了性能上的优化,也解耦了Executor 对本地盘的依赖,各种 pod 的机型都可以运行 Spark 作业。另外,完美支持动态资源,且多副本特性可以保证即使有Executor 挂掉,也不会带来 stage 重算等问题。

K8s上没有整套Hadoop集群,要实现SparkSQL元数据管理,需要部署Hive Metastore;要实现MySQL数据入湖,需要部署Sqoop;要实现权限管理与审计,需要部署Ranger等,构建极为复杂。
而Spark on ACK可以无缝对接阿里云DLF,完美解决上述问题。它提供了统一的元数据权限控制,Spark 不需要自己维护组件等,可以直接对接 DLF 做元数据管理,免去了很多组件运维的问题,并且用户可以快速上手,是一个很好的引擎搭档。
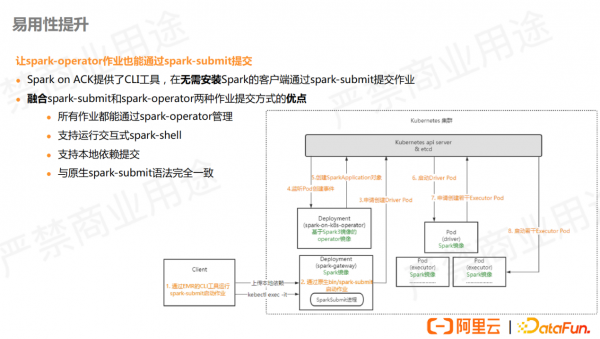
此外,在提交方式上我们也提供了新的方案,我们提供了一个 CLI 工具,可以直接以 spark-submit 语法提交 spark作业, 同时也会记录到 operator进行管理,集成了两种提交方式的优点。
集群提交 Spark pod 时,会反向监听 pod 创建再注册回 Spark operator ,使用内部改造过的 Spark operator 来实现该功能,更具易用性。
四、Serverless Spark在阿里云DLF的实践
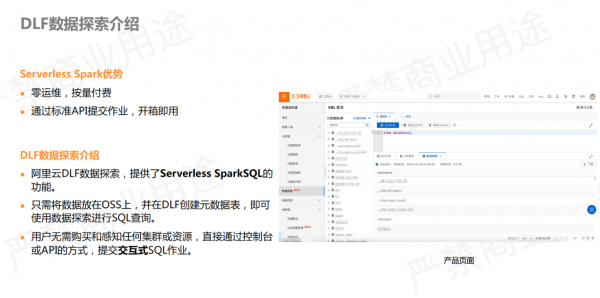
Serverless Spark意味着用户无需感知任何机器节点,只需通过标准的 API 方式直接提交作业即可,实现了零运维以及按量付费,非常适合中小型客户。
阿里云DLF 还提供了数据探索的功能,它是标准的 Serverless SparkSQL,适用于交互式查询。只需将数据放到 OSS 上,并在 DLF 创建好库表,即可直接使用 SQL 在控制台上进行交互式查询。
上图右侧为产品界面截图,是标准的 SQL 工作台,用户可以在平台上直接做分析查询。
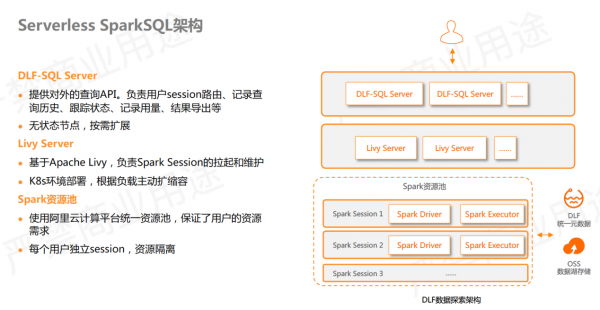
Serverless SparkSQL实现架构如上图所示。
最上层的 DLF-SQL Server是管控服务,对外提供查询 API ,为无状态的在线服务。下一层利用了Apache Livy 做交互式查询的会话创建和维护,部署在 k8s 环境里,可根据负载主动扩缩容。最下层 Spark 运行在内部的机器资源池里,它阿里云内部统一的资源池,与阿里云 maxcompute 共享,可以最大程度保证用户资源的需求。
针对每个用户的 SQL 查询都会提供独立的 Spark Session,意味着它们是不同的 Spark application ,用户之间的隔离性和安全性能够得到保证。
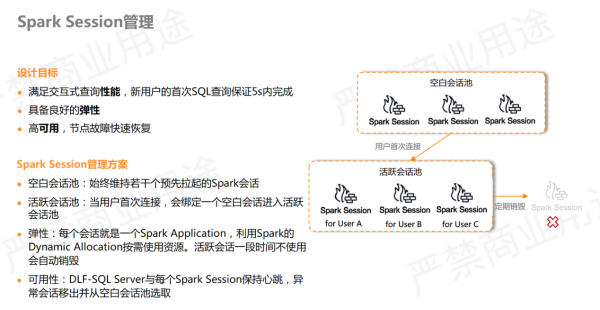
作为交互式查询,Spark Session在设计上有以下几个目标:
满足交互式查询性能,新用户首次SQL查询保证5s内完成。
具备良好的弹性。
高可用,节点故障快速恢复。
因此需要对 Spark Session做好管理。我们额外将 livy 拉起的 Spark Session分为了几种类型:
空白会话池:始终维护若干个空白会话,保证用户查询时无需现场创建 Spark 作业,能够最大限度地提高查询性能。
活跃会话池:用户首次查询时,会从空白会话里选中一个并标记为用户专属的活跃会话,进入活跃会话池。一段时间之内,如果用户查询不再提交或查询后超时,则会将活跃会话从活跃会话池销毁,自动关闭,避免了资源浪费。

针对Livy Server也进行了部分优化。
原生Livy默认只能运行一条语句,后续语句需要排队等待。为了提高并行度,我们改进了Livy 的状态管理,搭配 Spark 的fair scheduler ,可支持多条语句并行执行。
为了保证用户首次查询的性能,在空白session创建之初会进行自动预热。
Livy 的查询报错信息透出不全,默认只取 error 的第一行,我们对查询错误信息页进行了优化,将完整的异常信息返回,便于用户查询、定位。

为了保证用户体验,我们对数据探索的功能细节上也做了很多优化。比如自动对接 DLF 数据湖权限,阿里云子账号登录后,会自动根据子账号做鉴权,只能查询自己有权限的 table ,适合分析师多用户的场景。
数据湖格式方面,对delta、Hudi、Iceberg内置提供了支持,用户可直接写 SQL 查询,无需额外配置参数。每个湖格式都要配置自己的 SQL extension 做 SQL 拦截,三种格式在配置上会存在冲突。因此我们在湖格式层面做了优化和兼容,保证了互操作的顺滑性。
另外,提供了后台自动导出功能,默认内置了TPC-DS数据集,可通过映射的方式快速创建数据集库表。
|