7月,特斯联“九章人工智能算法赋能平台”计算机视觉基础模型核心算法,在国际顶级会议——2021国际计算机视觉大会(ICCV 2021)赛事中,击败众多强敌,跻身赛事排名前10%。竞逐者包括:字节跳动人工智能实验室、中国移动研究院、日本最大移动通信运营商NNT DOCOMO,以及清华大学、武汉大学、中国科技大学、墨尔本大学等69家国际大型企业、顶尖高校及研究机构。
坚持深耕、不断开拓人工智能最前沿算法,是特斯联斩落豪强,载誉而归的秘笈。本期“先锋科技场”将首次揭秘该行业领先算法。
大势所趋
随着全球人工智能产业高速发展, 人工智能(AI)近年被抽象成多种算法应用于不同领域。AI已全面进入机器学习时代。AI未来发展将是关键技术与产业的深入结合——单纯算法已无法满足更细分领域及行业对AI的需求,尤其在万物互联的AIoT(人工智能+物联网)时代,越来越多的订制化AI需求亟需解决。
原有开发模式实际已成为新形势下AI发展的瓶颈。当前,用户AI订制通常遵循“找公司-对需求-交付研究-算法产品化编码-上线使用”流程。这往往导致研发周期长、研发成本高,难以满足AIoT时代各行业用户AI产品开发需求。
对此,AI开放平台应运而生。其能集成AI算法、算力与开发工具,通过接口调用,使企业、个人或开发者高效使用平台AI能力,实现AI产品开发及赋能。随着大量AI厂商高速崛起,中国在技术平台领域已逐渐摆脱对海外厂商的依赖,涌现出多家AI开放平台。
虽然我国目前AI开放平台发展势头良好,但现有平台在用户规模、使用场景、用户技术基础等多个方面,仍然受限。这些平台均主要针对专业AI开发者设计,对AI零基础用户开发人工智能产品“不甚友好”。
此背景下,特斯联核心算法研究团队开发出普适性AI算法开放平台——“九章AI算法赋能平台”。它力克半监督、标签内容以及“联邦学习”(Federated Learning)等方面的核心技术难点,实现了CV(计算机视觉)、NLP(自然语言处理)、推荐预测、知识图谱算法的自训练。
九章平台可针对多场景及各规模用户(尤其可针对AI零基础用户),进行零代码、低代码自有算法孵化,颠覆已有AI研发人员开发模式,显著降低AI研发成本及周期。
在业界备受瞩目的校企合作方面,近年来各方努力已获成效,但仍有较大提升空间。目前,企业对高校研究成果颇感兴趣,需求较大;高校亦希望其研究能够解决实际行业问题,故十分渴望行业课题导入。但是,高校研究成果进行行业落地时,往往水土不服;高校产学研课题亦往往随着学生毕业被迫中断,持续性堪忧。
特斯联“九章AI算法赋能平台“可在弱监督体系下,能够实现平台和训练模型算法有效对接。使基于训练算法模式的校企需求对接,取代“向企业提供推理算法代码”这一传统模式。不仅如此,该平台可实现算法积累与深化。
本期“先锋科技场”就将揭秘九章AI算法赋能平台的核心技术之一——基于半监督的CV自训练学习算法。
甄选模型
监督学习技术通过学习大量训练样本,构建预测模型。其中每一训练样本均被贴上明确标签,显示其真值输出。尽管当前技术已取得巨大成功,高数据标注成本常导致诸多任务无法获得强监督信息(如“全部真值标签”等)。因此,采用半监督学习,通常是执行实际任务的更佳方案。
半监督分为三类——不完全监督、不确切监督、不准确监督。特斯联九章AI赋能平台致力于让AI能力偏弱或“贫乏”用户,也能拥有AI算法孵化服务能力。因此,弱化人工参与算法训练尤为重要。
但不同半监督类型亦存在自身短板。不完全监督若只拥有少量被标注数据,不足以训练出优秀模型。不确切监督仅能满足已给定监督信息、但信息不够精确的场景。不准确监督在监督过程中,会出现被标注数据存在错误监督信息的情形。三类半监督模式人工干预较大,无法形成自训练学习算法体系,无法达到普适性AI算法开放平台需求。
为构建基于半监督的自训练学习算法,特斯联核心算法研究团队主要采用基于Transformer模型的Swin Transformer作为骨干模型,以此搭建特征学习基础算法,进而构建自训练体系。此外,团队通过参加国际计算机视觉大会(ICCV)等国际顶级会议,有效验证了基于半监督的CV自训练学习算法在实际产业应用中的贴合度,并载誉而归。
深耕算法
特斯联核心算法团队针对上述三大半监督类型难题,将主动学习、半监督学习、多示例学习、带噪学习等技术引入自训练体系,最大限度从已知标签样本特征中,挖掘潜在内嵌信息,反哺至未知标签数据,从而减少人工干预。
特斯联以Swin Transformer为骨干模型,针对半监督,设计可学习样本全局及局部“特征学习模块”。
而选用Transformer为骨干网络,则可使输出的全局特征信息更为丰富,使“全局特征相似度学习模块”从样本特征中挖掘出更多信息。此外,“局部特征细粒度学习模块”聚焦样本局部特征,可与Transformer形成互补,统一对外提供基准骨干网络。
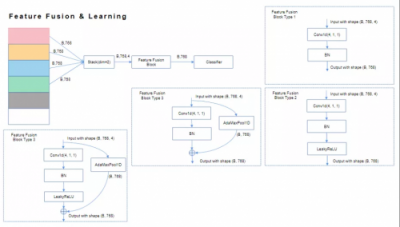
特征学习模块方面,特斯联基于BNNeck,采用“全局+局部”模式展开研究。全局层面,通过度量学习(Circle Loss + Center Loss)提取全局特征。局部细粒度特征学习层面,则首先计算每一局部模型间相关性,随后交叉融合局部模块相关性较高的特征,输入至各局部细粒度分类器,学习相应局部细粒度特征。如图所示,交叉融合可分为如下四种:
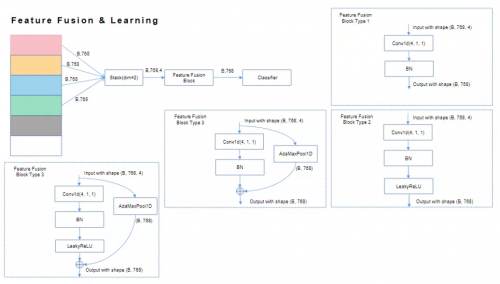
接下来的重点,为构建自训练体系。其主要分为两个阶段。第一阶段——强监督训练:利用少部分数据,对以上特征学习算法作初步强监督训练,降低后期自训练难度,提高自训练性能。第二阶段——标签内容生成:通过主动学习、半监督学习、带噪学习等技术,充分利用余下的大部分数据。
在此,将不再赘述强监督训练。标签内容生成工作,则会从主动学习/无监督学习、半监督学习两个方面展开。
主动学习/无监督学习分为四个步骤。旨在通过“挖掘小部分数据,带动大部分数据”,解决半监督下不完全监督短板。在有限的平台资源上,令大部分未标注数据高效得到相应标签。

半监督学习方面,通过以上无监督学习能够获得可靠性强,且具有标签的Query子集和Gallery子集G*。但两者均仅有缺少局部细粒度标签的弱标签信息。通过半监督学习实现L、G*,以及带有局部细粒度标签的训练集数据T,可对特征学习模型作全量调优。随后,在S=[L,G*,T]上寻找更优局部细粒度学习器;并利用训练集数据分布上的局部细粒度子模型,建立多个局部细粒度学习器,对未标签样例加注标签。局部细粒度学习器可基于其未更新前对L、G*所生成的局部细粒度标签,以及更新后所预测的结果,计算损失值进行学习。这一方面使L、G*在某种层面上,补充了T可能缺失的潜在信息;另一方面可通过学习器,帮助模型在L、G*上挖掘局部特征。
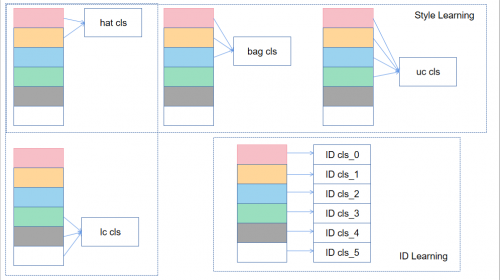
多轮、细致的实验结果证明:主动学习、半监督学习在解决半监督下的不完全监督问题中,表现稳定;多示例学习方法在不确切监督问题中表现稳定;带噪学习方法在不精确监督问题中表现稳定。
|