跨越速运集团有限公司创建于2007年,目前服务网点超过3000家,覆盖城市500余个,是中国物流服务行业独角兽企业。跨越集团大数据中心负责全集团所有数据平台组件的建设和维护,支撑20余条核心业务线,面向集团5万多员工的使用。目前,大数据中心已建设数据查询接口1W+,每天调用次数超过1千万,TP99在1秒以下。我们利用DorisDB作为通用查询引擎,有效解决了原架构大量查询返回时间过长,性能达不到预期的问题。
“作者:张杰 跨越集团大数据运维架构师,负责集团公司大数据平台的维护和建设”
一、业务背景
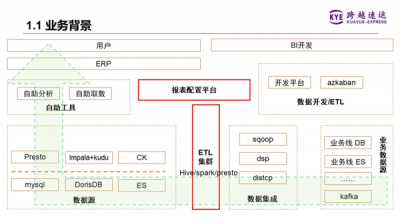
1、总体架构
我们原始离线数仓的总体架构如下图所示,数据从各个业务线的数据库,比如MySQL等,通过数据集成工具汇聚到ETL集群(即Hadoop集群),再使用Hive、Spark、Presto等批量处理引擎进行数据仓库的分层处理,然后将DW层和ADS层的数据推送到各种不同的查询引擎。
在这些查询引擎之上,有个统一的查询API网关,应用层的自助分析工具或ERP系统前端通过调用这个API网关,将数据内容呈现给用户。

二、业务痛点
该系统最大的痛点是查询性能问题。公司对大数据查询接口的响应延迟是有考核的,期望99%的查询请求都能在1秒内返回,比如页面ERP系统、手机端各类报表APP,用户会随时查看数据并进行生产环节调整,过慢的查询响应会影响用户体验,甚至影响业务生产。针对复杂的SQL查询场景,之前采用的Presto、Impala+Kudu、ClickHouse等系统,是远远达不到预期的。另外,针对各种复杂的数据分析业务场景,引入很多不同组件,导致了维护和使用成本非常高。
因此,我们急需一个新的查询引擎,能统一查询引擎,解决性能查询问题,降低使用和维护成本。
三、OLAP引擎选型

第一阶段,在2019年,跨越集团大数据中心使用Presto作为通用的查询引擎。此阶段集团大数据中心数仓层基本用的是Hive,Presto可以直连Hive的特性让我们无需做过多的改造,就可以直接生成查询的API。从性能角度考虑,我们也会将数仓中的部分数据拷贝至独立的Presto集群,和数仓ETL集群进行资源隔离。这套架构运行一年多之后,随着业务需求越来越复杂,数据量越来越大,该基于Presto构建的集群性能急剧下降。
第二阶段,为解决Presto集群性能不足的缺陷,我们基于ClickHouse开始构建新的通用查询引擎。2020年我们使用ClickHouse构建了大量大宽表,将此前需要多层关联的查询逐步迁移到ClickHouse集群。通过这种方式,我们确实解决了此前面临的性能问题。但与此同时,我们需要建设越来越多的大宽表,操作繁琐运维困难。并且这种数据模型无法随业务需求变化而快速改变,灵活性差。
第三阶段,我们在2021年开始寻找其他能满足我们需求的OLAP引擎,此时我们发现了DorisDB这个产品。首先关注到DorisDB的单表、多表关联查询的性能都非常优秀,能够满足我们对查询延时的需求;DorisDB支持MySQL协议,让我们开发同事在开发接口的时候学习和使用门槛非常低。另外,DorisDB还具备支持按主键更新、支持多种类型外表、部署运维简单以及支持丰富的数据导入方式等特性。这些都是我们所需要的。
因此,我们开始逐步将以往的分析业务迁移到DorisDB集群上,将DorisDB作为大数据中心的通用查询引擎。
四、DorisDB在跨越集团的应用
1、在线场景应用
当前我们每天在线数据接口的查询请求量已经超过千万。在引入DorisDB前,我们用了8到9种查询引擎来支撑各种在线业务场景。大数据量的明细点查场景使用ElasticSearch作为支撑;对于查询维度固定、可以提前预计算的报表场景,会使用MySQL;对于SQL查询复杂,如果多表Join、子查询嵌套的查询场景,会使用Presto;实时更新的场景,则会使用Impala+Kudu的组合来支撑。

引入DorisDB后,目前已替换掉Presto和Impala+Kudu支撑的场景。ElasticSearch、MySQL以及ClickHouse,后续也可能会根据业务场景实际情况逐步替换为DorisDB。
下面详细介绍一个实际在线场景的典型案例。如上图,我们在原Presto系统上有一个包含200个字段的宽表聚合查询。由于业务需求比较复杂,SQL语句有600多行。我们曾希望从业务逻辑上进行优化,但是并不容易,不能因为系统能力问题就一味要求业务方来迁就。现在我们使用10个节点相同配置的DorisDB替换原15台相同配置服务器的Presto集群后,在没有做什么业务逻辑变化的情况下,使用DorisDB明细模型,凭借DorisDB本身的高性能将查询延时从5.7秒降低为1秒,性能是原Presto集群的近6倍。
2、OLAP场景应用
跨越集团的OLAP多维分析平台是我们自研的一套BI系统。用户可以根据自己业务场景选择字段以及关联条件等,以拖拉拽的方式生成数据的表格或图表。最早我们支撑OLAP多维分析的后端引擎是Presto,在这类场景下的性能确实不尽如人意。因为性能问题,我们也没办法将这个工具推广给更多的用户使用。我们将后端查询引擎替换为DorisDB后,性能提升非常明显。我们将OLAP多维分析平台向整个集团推广,受到了越来越多的用户好评。
OLAP多维分析主要是离线分析为主,以客户离线分析场景为例,数据经过ETL处理后,生成对应的DW层或ADS层数据,再通过Broker Load将数据按天导入DorisDB中。我们使用星型模型构建客户主题域,客户主表以明细模型在DorisDB中建表,同样以明细模型创建维表。这样用户就可以在前端对客户主题域的各种指标、各种维度进行拖拉拽,生成对应的表格和图表。

在客户离线分析场景下,我们DorisDB上线前后业务逻辑没有进行太多调整前提下,TP99从4.5秒下降到1.7秒,性能是原来的三倍(后续我们将尝试开启CBO优化器,预计会有更大性能提升)。绝大多数场景都能实现1s内返回,大大提升了用户的体验。

利用DorisDB的实时分析能力,我们还构建了实时OLAP多维分析。以运单实时分析场景为例,原本我们是用Hive每两小时跑批的方式来实现的,将固定维度数据算好,结果写入Presto上提供查询,逻辑类似于离线数仓,并不能称为真正的实时。引入DorisDB后,我们调整数据流转逻辑,通过监听Binlog将数据写入Kafka,再通过Rontine Load的方式消费Kafka,将数据实时写入DorisDB中。我们使用更新模型建立实时运单主表,将运单ID设置成主键,这样每一笔运单更新后,都能实时更新到运单主表中。和离线分析场景一样,使用星型模型构建运单主题域。

通过这样的调整,以往每两小时更新数据的运单主题域,现在可以实现秒级更新,成为名副其实的实时分析。另外此前需要依赖预计算,维度都是固定的,很多分析上功能受限。经改造后,除了大幅提升“实时”体验外,在分析灵活性上的提升也非常明显。实时体验和灵活分析也成为OLAP多维分析平台工具在实际服务中最大的亮点。
五、后续规划
1、为了避免部分慢查询影响整体的集群性能,后续会搭建多套DorisDB集群,按业务场景进行物理资源隔离。
2、DorisDB查询Hive外表的功能,经内部测试比Presto查询Hive的性能要好,后续会将原本Presto查询Hive的场景无缝迁移到DorisDB上。
3、目前我们在DorisDB上写入了很多实时数据,这些数据需要进行聚合等处理,我们正在尝试使用调度工具,在DorisDB上进行5分钟级、10分钟级的轻量ETL处理。
4、开启DorisDB的CBO优化器,进一步提升查询性能。
最后,感谢鼎石为我们提供DorisDB这么好的产品,满足了我们对性能强、功能全的查询引擎产品的要求;感谢鼎石一直以来提供的技术支持,解决了我们在使用中遇到的各类问题。
|