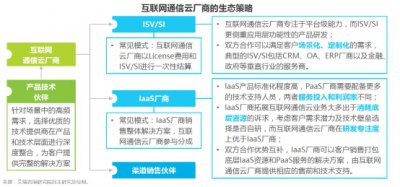
大数据会影响质量,因为大数据的定义特征是数量,种类和速度使验证变得困难难以捉摸的“第四”,即准确性组件(关于数据可靠性),由于可能会聚集大量的数据源而面临挑战,每个数据源可能会遇到不同的质量问题,大数据还释放了可能引入新类型数据错误的新的和更复杂的查询的可能性,同时由于非结构化数据比结构化数据具有更大的不确定性,因此非结构化数据会产生问题,并且机器学习算法倾向于充当“黑匣子”,其中数据中包含的偏差可能永远不会消失。您的数据质量工具箱尽管已经开发了许多工具来解决数据质量问题,但是如果不小心应用自动条目更正本身可能会降低数据质量,所有影响数据清晰度的因素(例如准确性,一致性,及时性,重复性,易失性,完整性和相关性)都可能导致进一步的问题,因为企业会更正数据并将其调整为适合处理的形式,每个转换都可能会丢失可能与给定查询相关的信息,当前的数据质量工具由主要的分析公司,利基公司和开源提供,它们提供诸如数据清理,数据概要分析,数据匹配,数据标准化,数据丰富和数据监视之类的功能,诸如金融服务之类的利基工具专注于特殊类型的问题,并且正在开发新的工具,这些工具采用机器学习技术进行数据分类和数据清理。在将大数据与机器学习相结合的地方,还会出现其他质量问题为规范化数据而进行的更改可能导致机器学习算法在解释上出现偏差,大型数据存储中错误发生的频率相对较低,可以说使得对数据质量检查的需求变得不那么重要了,但现实情况是,质量问题只是转移到了其他领域,自动校正和一般假设可能会在整个数据集中引入隐藏的偏差。
保持真实必须根据业务需求了解数据质量,在某些情况下,需要采用涉及无数变量的严格方法,但是对于许多查询而言,更宽容的方法是可以接受的,在及时性和准确性,查询值和数据清理以及准确性和可接受的错误之间始终需要权衡取舍,在复杂的数据和分析环境中,没有一个适合所有大小的空间,查询需要不同级别的准确性和及时性。以一种方式构造的数据可能适用于某些用途,但会导致其他用途的结果不准确或有偏差。数据质量的最终测试是它是否产生所需的结果这要求进行严格的测试,并考虑引入错误的潜在原因,尽管用于数据清理,规范化和整理的工具越来越受欢迎,但可能的因素的多样性意味着这些过程不会在短期内完全实现自动化,随着自动化的普及,您必须确保自动化解决方案不会由于转换规则而在数据流中引入新问题。确定性的不确定性由于数据集和结构化数据有限,因此数据质量问题相对明确,创建数据的过程通常是透明的,并且会遇到已知错误:数据输入错误,表格填写不正确,地址问题,重复等,可能的范围相当有限,并且要严格定义处理的数据格式,随着机器学习和大数据的出现,数据清理的机制必须改变,除了更多,更快的数据外,非结构化数据的不确定性也大大增加,数据清理必须解释数据并将其放入适合处理的格式,而不会引入新的偏差,此外质量过程将根据特定用途而有所不同。数据质量比绝对质量更重要
根据研究目标和业务目标,需要使查询与数据集更好地匹配,数据清理工具可以减少数据流中的一些常见错误,但始终存在潜在的意外偏见,同时查询需要及时且负担得起,从未迫切需要一种谨慎的数据质量方法,机器学习和高级软件工具无疑提供了解决方案的一部分,从而有可能为质量问题带来新的方法,但是没有万能药,更高级别的复杂性意味着需要更仔细地检查数据。来源:CPDA数据分析师网 / 作者:数据君 /
|