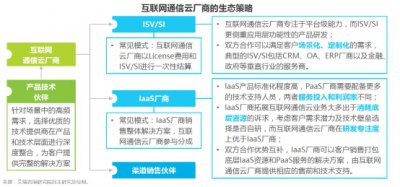
9月18日,2020云栖大会上,阿里云正式推出大数据平台的下一代架构——“湖仓一体”,打通数据仓库和数据湖两套体系,让数据和计算在湖与仓之间自由流动,从而构建一个完整的有机的大数据技术生态体系。为企业提供兼具数据湖的灵活性和数据仓库的成长性的新一代大数据平台,降低企业构建大数据平台的整体成本。

大数据技术从本世纪初发展至今演进出了数据仓库和数据湖两种趋势,前者通常指云厂商提供的基于大数据技术的一体化服务,后者通常是由一系列云产品或开源组件共同构成的大数据解决方案。
当企业处在初创阶段,灵活性就非常重要,数据湖的架构更适用。当企业逐渐成熟,成长性成为最关键因素,数据仓库的架构就再适合不过了。那么,数据仓库和数据湖是否只能是一道单选题?能否有一种方案同时兼顾数据湖的灵活性和云数据仓库的成长性?
阿里巴巴集团副总裁、阿里云计算平台负责人贾扬清表示,MaxCompute湖仓一体方案打破了数据湖与数据仓库割裂的体系,在架构上将数据湖的灵活性、生态丰富与数据仓库的企业级能力进行融合,从而构建数据湖和数据仓库融合的湖仓一体的全新计算平台。MaxCompute湖仓一体方案不仅可广泛用于支持超大规模的机器学习和深度学习,还能帮助企业高效提升自身大数据能力,实现敏捷运营,降本增效。
据悉,MaxCompute在原有的数据仓库架构上,融合了存储计算一体化数据仓库和云上存储计算分离的数据湖,最终实现了湖仓一体化的整体架构。在该架构中,尽管底层多套存储系统并存,但通过统一的存储访问层和统一的元数据管理,向上层引擎提供一体的封装接口,用户可以Join数据仓库和数据湖中的两张表,同时整体架构还具备统一的数据安全、管理和治理等中台能力。
在技术融合过程中,MaxCompute不仅实现了快速接入、统一数据/元数据管理、统一开发体验、自动数仓四个关键技术点,更持续提升了核心性能,在2020 TPCx-BigBench中,MaxCompute基于英特尔至强可扩展处理器在100TB规模保持性能不变的情况下,成本较去年下降了40%;30TB规模下,性能提升50%以上,成本下降了30%以上。
微博是“湖仓一体”的尝鲜者。此前微博拥有Hadoop数据湖和阿里云大数据及AI两套异构的大数据平台,且两套平台在集群层面完全割裂,数据和计算无法自由流动。为了解决这些难题,微博基于阿里云构建了湖仓一体化的AI计算中台,摆脱了繁重的数据搬迁,使得微博的数据工程师和算法工程师轻松无缝的借助阿里巴巴成熟的超大规模算力和算法赋能业务提效。同时,将MaxCompute云数据仓库(结构化数据)与数据湖(非结构化数据)构成闭环,极大提升了AI类作业效率,产生巨大的业务价值。
阿里云自研云数据仓库MaxCompute历经近10年技术沉淀,不仅稳定支撑阿里巴巴集团的数据存储和数据计算业务,更是云上客户大数据平台的重要组成部分。此次湖仓一体发布,为企业提供了一种更灵活更高效更经济的数据平台解决方案,既适用于全新构建大数据平台的企业,也适合已有大数据平台的企业进行架构升级,切实以技术加速了企业的数字化重构。
据了解,本次云栖大会上,贾扬清还首次发布阿里云云原生数据湖体系,基于对象存储OSS、数据湖构建Data Lake Formation和云原生开源大数据产品E-MapReduce的强强组合,提供存储与计算分离架构下,涵盖湖存储、湖加速、湖管理和湖计算的企业级数据湖解决方案。以及宣布MaxCompute和Hologres产品融合升级,提供离线、实时、分析、服务一体的数据仓库。
|