��/������Ϣ���ڿƼ��ֲ�ʽ�ܹ�ר�� Ѧ����
�ἰ2020����ڿƼ��ȴ�,“�ֲ�ʽת��”ʵ����һ��������ҵ������Ҫ�ֲ�ʽ����,��Ӧ��ҵ��ת��,���㷢չ����������ҵ�ڽ��зֲ�ʽת��ʱ,����Ҫ��עӦ�ò�ķֲ�ʽ(���������ʽ����)��,���ݲ�ķֲ�ʽҲ����Ҫ����ɲ���,���Ľ���Ŀ��۽������ݵķֲ�ʽ��
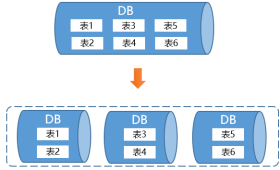
�ֲ�ʽ�ĺ��������ǰѴ�IJ��ΪС��,Ȼ���ö�������ڵ�ȥ����,�����еļ���һ�������ϻ���������һ�ݡ����嵽���ݲ���Ҳ��һ��,����������ݲ���ַ�Ϊ“��ֱ�з�”��“ˮƽ�з�”���ִ������,��ν�Ĵ�ֱ�зָ�����ǽ���ͬҵ������ʹ�õ�“��”��ֵ���ͬ�����ݿ���,һ�������Ǹ������������ʹ��,����ͼ��ʾ:
<ͼ1 ���ݴ�ֱ�з�>
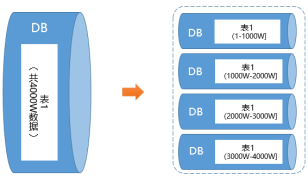
��ˮƽ�з����ǰ�“���е�����”����һ���IJ��Խ��в��,��������Ҫ�ǽ������������������,����ͼ��ʾ:
<ͼ2 ����ˮƽ�з�>
���ĵ����ݷֲ�ʽ�����“����ˮƽ�з�”�ķ�ʽ��̸�ġ�
���ݷֲ�ʽ�ķ����볢��
�����ݷֲ�ʽ������ʹ��,�Ͳ��ò��ᵱ�꽨�е��ϱ�����,��ʱ���а�ȫ�������ݷ�Ϊ�ϱ���������,Ȼ��ÿ�����ĵ�ҵ��ϵͳֻ���ʸ������ĵ�����,������ֿ��ϱ����ĵ�ת�˵Ļ�,��������ģ������ת�˵ķ�ʽͨ����Ϣ���н��д������������ݵ��ӽ�����,���Ѿ��ǽ�ȫ�е����ݰ������ά�Ȳ��Ϊ������,����˵,��Ӧ���������ݷֲ�ʽ������Ӧ�á�
2014��,���ڵ�һ����Ӫ����——��������ʽ����,��������Ҫ��������������ҵ��,��������Ѷ������,�������ȻҪ��Դ�����������ս,������ϵͳ�����ʱ��,�����в����˵�Ԫ�����������,�������������ݰ��ͻ��Ų��Ϊ���,ÿһ���ö��������ݿ����,����ÿ���ֿ������ֻ�ܱ��̶���Ӧ��������,����ͼ��ʾ,���������Ĺ̶�Ӧ��+����ķֿ����һ��DCN,Ҳ����һ����Ԫ�塣�����ּܹ���ϵ��,���еķ������������,�����ȷ���“GNS”,�����֪�õ��ĸ�DCN��ִ��,����“GNS”������ܹ��е�λ�þͷdz���Ҫ,������ȶ��ԡ��ɿ��ԡ�����,�Լ�ӳ���ϵ�б仯�������һ���Ե�,������˺ܸߵ�Ҫ��
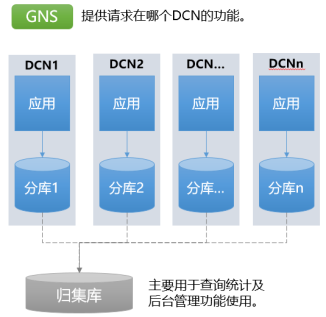
<ͼ3 ���ݷֲ�ʽ�ĵ�Ԫ��ģʽ����>
���ڸ�����Ԫ����ȫ����,�漰�������Ԫ��Ľ����������ͻ��ø����ӡ�������õ�“ת��”�Ĵ�������������:
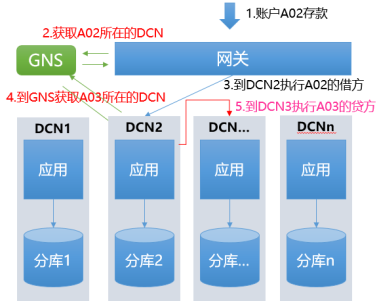
<ͼ4 ��Ԫ��ģʽ�µ�ת������ʾ��ͼ>
��ͼ�к�ɫ��������������ֶ��Ǹ��üܹ��������еĹ�ϵ���ڽ���ҵ���л���һ��ҵ��,�����佻�������Dz����ͻ��ŵ�,����,��ѯһ�����ڵ��¿��˻�,�����䲻���ͻ���,Ҳ����ͨ��GNS�������·��������DCN,��������ҵ������ѯ������,һ�㶼�Ǹ������зֿ�ġ�����,�����еĴ���˼·��:������ҵ��������ͳ�����ҵ��,ͨ�������зֿ�����ݹ鼯��һ��,�������ҵ���ֱ�Ӳ�ѯ“�鼯��”(��ͼ3�еĻ�ɫ����)�����˽�,�������Ѿ��������“�鼯��”��TiDB���ݿ�����滻��
����“��Ԫ��”��˼·,������һ��ȫ�м��ļܹ�,�������,��ʵ�����ݷֲ�ʽ��һ�ֽ������,ֻ��������ܹ���������������ܹ�ֻ�������ݵIJ�ּ��ṩ·��֧��(ͨ��GNS����),����������ȫ������ҵ�����ϵͳ�ܹ�������(“�鼯��”����һ������),���ԲŻ������ҵ��ʵ�ֺ�ϵͳ�ܹ�����Ƚϸ��ӡ������ɷ��ϵ���������ȷʵ�ǹ��������ݷֲ�ʽ����ĵ�һ�δ��ģ��Ӧ��,��Ȼ����������������ܹ�������һЩֵ����ȶ�ĵط�,����2015��,��ҵ�ڷֲ�ʽ�Ÿո���ʱ��,������������Ѿ��dz��ֲ�ʽ�����һ�δ���,Ҳ����ƶ��˹��ڽ�����ҵ�ֲ�ʽ�ķ�չ,�����ݷֲ�ʽ����һ����Ҫ����̱���
���ݷֲ�ʽ�����̽��
�����ݷֲ�ʽ��̽��������,���ֽ�������ٻ���š�����,�Ƚ�������ʵ�ַ�ʽ�����¼���:
1���ֲ�ʽ���ݷ������
“��Ԫ��”�Ǵ�����ܹ����ӽǽ�������,��ͬ�����ǽ���“����ˮƽ�з�”,��һ�ֵ���˼·����Ӧ�üܹ��ڲ��������ͳ��ϵͳʵ�ֻ�������Ӧ��ֱ�ӷ������ݿ�,���ַ����ij���,ҵ����Աһ����Ҫʵ��ҵ����,ͬʱ��Ҫ����Ӧ�÷����ĸ�����ķֿ�,���Դ���dz�����,����Ա������Ҫ��Ҳ�Ƚϸߡ����,˼·�����ɽ� “���ݵķֲ�ʽ�洢������”�Ĺ��ܴ�ҵ������а������,ʵ�ֶ�ҵ�����ĵ��������������롣“�ֲ�ʽ���ݷ������”�������ı�������չ,��������ģʽ�IJ��Ϸ�չ,�书�ܲ������Ա�֤����͵İ�����Ƭ����SQL�Ĵ���,�Բ�������Ƭ���ıȽϸ��ӵ�SQL��֧�ֶ�ҲԽ��Խ��,��Ȼ��ҵ��������ҲԽ��ԽС������ģʽ�����ݵķ���ģʽ��������ͼ,��������ɫ���־���“�ֲ�ʽ���ݷ������”λ��:
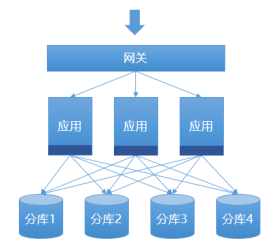
<ͼ5 �ֲ�ʽ���ݷ������ģʽ>
“���”ģʽ���Լ�����Ϊ�ǶԴ�ͳ�����ݷ��������������,��ʵ�����ݷֲ�ʽ�ķ��ʵ�����,����ʵ�ڲ��ĸ��Ӷ�Ҳ�Ƚϸ�,��ҵ��ϵͳ�������ݿ��������·û�в���Ӱ��,Ҳû�����Ӷ�������翪��,���Ҷ�ԭ�е����ݿ�DBA��Դ����ά��ϵҲ����û��Ӱ��,��������һ�ַdz���������Ч��ʵ�ַ�ʽ��
2���ֲ�ʽ���ݷ����м��
Ϊ�˼��ٶ�ҵ����������,���γ���“�ֲ�ʽ���ݷ������”��ģʽ,��������Ƕ����ҵ��ϵͳ�ڲ�,����,�������ڼ�����Ҫռ��Ӧ�õ�������Դ,��һЩ�Ƚϸ���SQL�Ĵ���������һ��������,����м����ģʽ������,��“�ֲ�ʽ���ݷ������”ʵ�ֵĹ��ܴ�Ӧ��ϵͳ�а������,������������ģʽ���Ƽ�,���������������Ҫ����Ӧ�ø��м����ͨѶ(������ʲôЭ��,��ҵ��ûӰ��),�����ڲ��Ը���SQL�Ĵ������Ӷȷdz��ߡ����ڸ�ģʽ���µ����л�������:
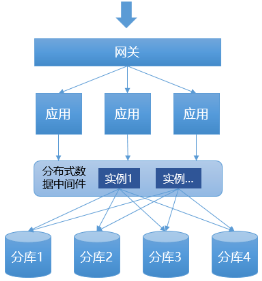
<ͼ6 �ֲ�ʽ�����м��ģʽ>
“�м��”ģʽ�����ŵ������Ӧ��ϵͳ֮��,���Զ�����ڵ㲿��,���Ա����Ӧ��ϵͳʹ��,����������������Դ���������Խ��бȽϸ��ӵ�SQL����,�����ϱ�“���”ģʽSQL��֧�ֶ�Ҫ�ߡ���ͬ�������Ƕ�������,�ڵ�����·�о�������һ�������罻��,���������������������,��Ҫ0.5ms�Ķ����,��Ȼֻ��0.5ms������,��һ��һ��������������Ϣ��ѯ,Ҳ�����Ͼ���0.5��1ms,����,����ӵ���SQL���ܺ�ʱ����,����Ҫ�����������еĻ��ڴ�����˵,��ͬSQL������ǰ����,����֮ǰ�ĵ�����Ӧʱ����40ms,��������м��ģʽ�Ļ�,������Ҫ��70��80ms�ˡ���Ȼ�ֲ�ʽǿ�������ڴ��������Ļ��������崦������������,�����嵽���ʽ�����Ӧʱ�����Ӱ��̫��,һ��ͻ����Dz�̫�����ܵġ�
3������MySQL�ķֲ�ʽ���ݿ�
�м��ģʽ,�����Ϻ��ʹ�õ����ݿ�����Ǹ��ֳ��õ����ݿ�,��һ�������Ǹ�MySQL���жԽ�,“�ֲ�ʽ�����м��”��“MySQL���ݿ�”������һ��ķ���Ӧ�˶���,ʹ֮���һ���ֲ�ʽ���ݿ�IJ�Ʒ��������,�䲻���߱�“�ֲ�ʽ�����м��”������,ͬʱ���ṩ������MySQL���ݿ�ļ�Ⱥ��������,�Լ����ĸ����걸�Ĺ���,ͬʱ���ڸ�MySQL���ݿ��������,��һЩ���ܵ�ʵ�ֻ�����,���Ը�MySQL���бȽ���Ķ���,��Ҳ�������ͨ�õ��м��ģʽ��һ�����ơ�������������,���ڱ����ϸ��м��ģʽ��û��̫�����𡣾�������:
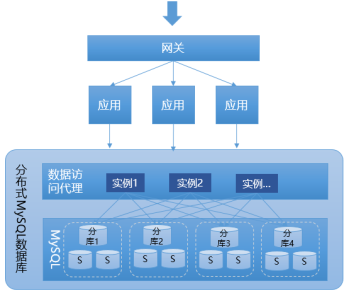
<ͼ7 ����MySQL�ķֲ�ʽ���ݿ�ģʽ>
����ģʽ�������ƾ���������һ�����������ݿ�����ṩ����,����������м��ģʽ+MySQL���ݿ�ķ�ʽ,��ģʽ�����ṩ�����ݷֲ�ʽ������,���һ��ṩ�˱Ƚ�רҵ��MySQL�ļ�Ⱥ����ά����������������ģʽ���м��ģʽһ����Ҫ�������һ����(����ͬ�ij��̵�ʵ�ֻ����й�)�Ķ������翪��,��SQL֧�ֶȷ���������������̫����졣
4������ȫ�����ݿ�������ϵ��NewSQL���ݿ�
ǰ���ᵽ�ĸ��ַ�ʽ����һ��ǰ������,���ǻ������г���Ĺ�ϵ�����ݿ⡣������ģʽ��ȫ��һ��ԭ���ķֲ�ʽʵ��,�佫�ֲ�ʽ������ֱ��Ӧ�õ����ݿ��ڲ��ļ��㼰�洢������,ʹ�������;߱��ֲ�ʽ�Ļ�����ͼ��TiDB�ļܹ�,���Կ�����ʵ�ֻ����������ͳ�����ݿ����ŷdz��������
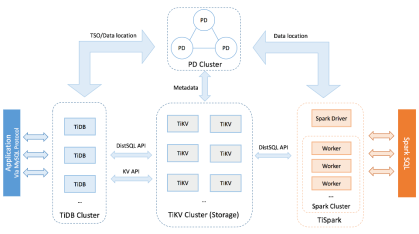
<ͼ8 TiDB������ܹ�>
��������ģʽ,Ӧ��ϵͳ������ȫ���䵱��һ�����ݿ�������,�����ڲ�ͬ����Ҫ���зֲ�ʽ���ݵļ���,�Լ��ֲ�ʽ���ݵĴ洢�ȡ���������ͼ:
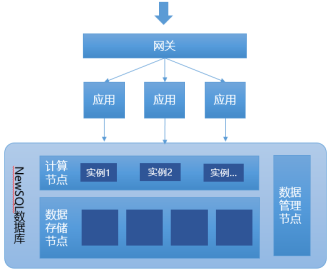
<ͼ9 ����NewSQL���ݿ��ģʽ>
����ȫ�����ݿ�������ϵ��NewSQL���ݿ�ģʽ���������Ƚ���ģʽ,���������ȫ�µ��������,����ʹ�����ֿ�����֮ǰ��ͳ�ķ�ʽ��ʹ��,����,��һЩϸ�ڲ������ͳģʽ������һ�������,������ʹ�õĹ����л�����Ҫ��������,������ʹ�õ�ʱ�����һЩ���⡣����,����ģʽ�Ͼ���һ����������,�����䷢չ������Ҫʱ������������,�������ֽζԽ�����ҵ��֧�����в�����Ҫ���������ĵط�,����Ҳ�������չ�Ĺ��ɡ�����һ���������ԭ���ķֲ�ʽʵ��,��ʵ����һ��DZ�ڵ�ǰ��,���Ƕ������Լ����̵Ĵ洢�ȷ���Ҫ���DZȽϸߵ�,��������Ӳ������Ŀ��ٷ�չ,��Щ������綼�ᱻ�ͳɱ��Ľ��������ʵ,Ӱ������ģʽ��ػ���һ������,������Ͼ����µ�����,�������Ҫʹ�õĻ�,�ͱ����ж�Ӧ��DBA��Դ,�Լ��Ƚϳ���ġ��걸����ά������ϵ���Ƚ����ҵ���,������ݿ⳧��Ҳ�ڻ����ƽ������̬Ȧ��֪ʶ��ϵ�Ľ��蹤����
���ѡ�����ݷֲ�ʽ��ʵ�ַ�ʽ
���϶������ݷֲ�ʽ��ʵ�ַ�ʽ,��Ҫ�����ʵ�ֵ�λ�ò�ͬ,“��Ԫ��”ģʽ��������ܹ������ʵ�ֵ�,“���”ģʽ����Ӧ�üܹ���ʵ�ֵ�,“�м��”ģʽ����Ӧ�ú����ݿ�֮��ʵ�ֵ�,�������ֶ���ֱ�������ݿ����ʵ�ֵġ������������ĸ��㼶ʵ��,�ֵ�˼·���������ݷֲ�ʽ�����⼯�н��,��ҵ��ϵͳ��������,��SQL֧�ֶȷ��澡���ܸ�ֱ�ӷ��ʴ�ͳ�Ĺ�ϵ�����ݿⱣ��һ�¡����Ƿֲ�ʽ���������ע������������Ҫì���Ǵ��������Ĺ�ϵ�����ݵ�����,������Դ�ͳ�Ĺ�ϵ�����ݿ�,����ЩSQL�ڷֲ�ʽ��ϵ��ʵ�ֵ��ѶȻ��DZȽϸߵ�,������IJ�ʵ��û�б�Ȼ��ϵ,��ʹ�������ݿ����ʵ�ֵ�,ͬ���Կ��������ڵ�����ݱ��Ĺ�����ѯ������ȶ��Ƿdz�������Դ�ġ�����,�ڷֲ�ʽ��ϵ��һ������ȡ���,��ʹ�ø����ʱ��˼�����Ҳ��Ҫ��ʱ���,���ԭ��һ�����ﳤ�̡ܶ�
����,����Ҫ����ҵ�����н��,�����������۵�Ҫ����100%���������������к���ϵͳΪ��,һ��Ƚϴ�ı�Ҳ���ǿͻ����˻���������ˮ����صı�,����,ֻ��Ҫ���漰��Щ���Ľ���������,Ȼ��Գ��õ���Ҫ�Ľ��װ��շֲ�ʽ�������������Ƽ���,ͨ������¶��⼸�����IJ���,��Ҫ���Ǵ�ȡ�ת��,�Լ��ͻ����˻���Ϣ��������ˮ��ѯ��,��Щ������ռ�����⼸�������н���90%�������ࡣ����Щ���������Ǿ��嵽ij���ͻ������˻���,����,��ʹ����������“�ֲ�ʽ���ݷ������”ģʽ�������ֿ��ֺõ�֧�����ֳ�������������һЩ������Ʒһ��,Ҫ�����Ĺ��ܷdz��ḻ,������������õ���ֻ�в���10%�Ĺ��ܡ�
δ��,���ݷֲ�ʽ��ȥ�δ�?����̸������ģʽ,��ʵû�о��Ե��������,���ӳ�Զ�ķ�չ��������,NewSQL��ģʽһ����δ���ķ���,����ĿǰNewSQL������HTAP��չ,�����ͬʱ֧��OLTP��OLAP�Ľ���,�������ҵϵͳ���������ܹ�Ҳ������Ƚϴ�ĸı䡣����,�䲻����ԭ���ķֲ�ʽ,Ҳ����ԭ������Ҫ��ɲ���,��������ҵ�ķ�չ����Ҳ��һ�µ�,���ڵ���,�仹�в��ٹ�����Ҫ��������,�����ǶԽ��ڳ�����֧�ַ��档����,����“���”ģʽ,������Ƕ����Ӧ���ڲ���������ʵ��,�����������,��SQL��֧�ֶ�Ҳ�������㳣�õ�����,������һЩ����ϵͳ�Ľ��跽��Ҳ�Ƿdz������,�䲻��Ҫ�����ɹ�һ���ֲ�ʽ���ݿ�,�����������ݿ���ά��ϵ����Ҫ��������������,���߱ȽϿ���������ģʽ,������Ϊ��ʹNewSQL������,“���”ģʽҲ�᳤�ڴ��ڡ�
|
|