��ͳ���ݺ�����������ս
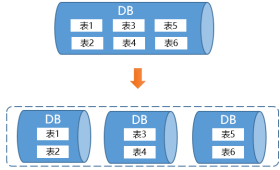
�������ݷ������˹�����Ӧ�õ��ռ�����ҵ����������������ҵ���������ҵ�����ݷ�������ԡ����ܺͳɱ���Ҫ��Խ��Խ�ߣ���ͳ������Hadoopϵͳ������ݷ���ƽ̨����������ҵ��Ҫ��Խ��Խ�����ҵ�����ݺ�Ϊ�������������ݴ���ƽ̨�����ݺ��ĵ��������Ǵ洢�ͼ�����룬�ܹ�����ϵͳ�ɱ�ͬʱ��ø��õ�ϵͳ��չ�ԡ�
���ݺ��ܹ�ʹ����ҵ������һ����������չ����ҵ������ÿ��չһ����ҵ�����һ�����ݿ���������ͳ���ݺ���������������Ȼ�������Ե�ȱ�㣬��ͳ���ݺ������ƴ洢����Ȼ�����˴洢�ɱ����������ݷ����Ĺ�������ȫ�����ƴ洢����������������������ɨ�裬���ַ�ʽֻ������ETL�����������ʱ�Ӳ����е�Ӧ�ã�ȴ��֧���뼶���ݼ�����ʱ�����ݷ����ȵ�ʱ�ӵķ���������
���ݺ�֧�Ŵ����ݷ����ͻ���ѧϰƽ̨
���˷���ͳ��Hadoop/Spark�����ݷ���ƽ̨�����ݺ�����Ҫ����AI�㷨��ģ��ѵ�������������ݹ鵵��������Ҫ��洢ϵͳ֧�ֶ���Э������������Ч�ʡ��������Զ���ʻģ��ѵ�������������У������ɼ�����Ƶ���״�������Ҫͨ���ļ������ӿڵ���洢��Ȼ��ͨ��HDFS�ӿڶ�����Ԥ������Ԥ���������ͨ���ļ��ӿ��ɼ������������AIѵ�������ܷ��棬�Ӷ��õ��µ��㷨��ģ�ͽ�����һ�ֲ��ԡ���Щ�����ǵ�һ�Ķ���洢��HDFS�洢�ܹ�֧�ŵģ���Ҫ��רҵ�Ĵ洢ƽ̨�ṩ����
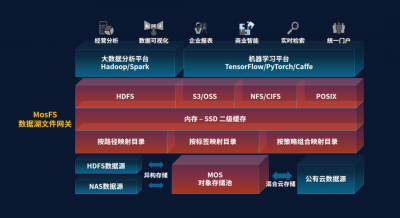
ɼ�����ݵ�MOS��������洢ͨ���칹�ɹܵķ�ʽ���������Ϲ������е�HDFS����Դ��NAS����Դ��ͨ������ƴ洢���������Խ��洢�ڹ����Ƶ�����Ҳ���뵽MOS����洢��ͳһ������ɼ�����ݽ��ڷ�����MosFS���������ݺ��ļ�������ϵͳ�ܹ���λ��MOS����洢��֮�ϣ�ΪHadoop/Spark�����ݷ���ƽ̨��TensorFlow/PyTorch/Caffe�Ȼ���ѧϰƽ̨�ṩԭ����HDFS�ӿڡ�S3/OSS����ӿڡ�POSIX�ļ��ӿڡ�
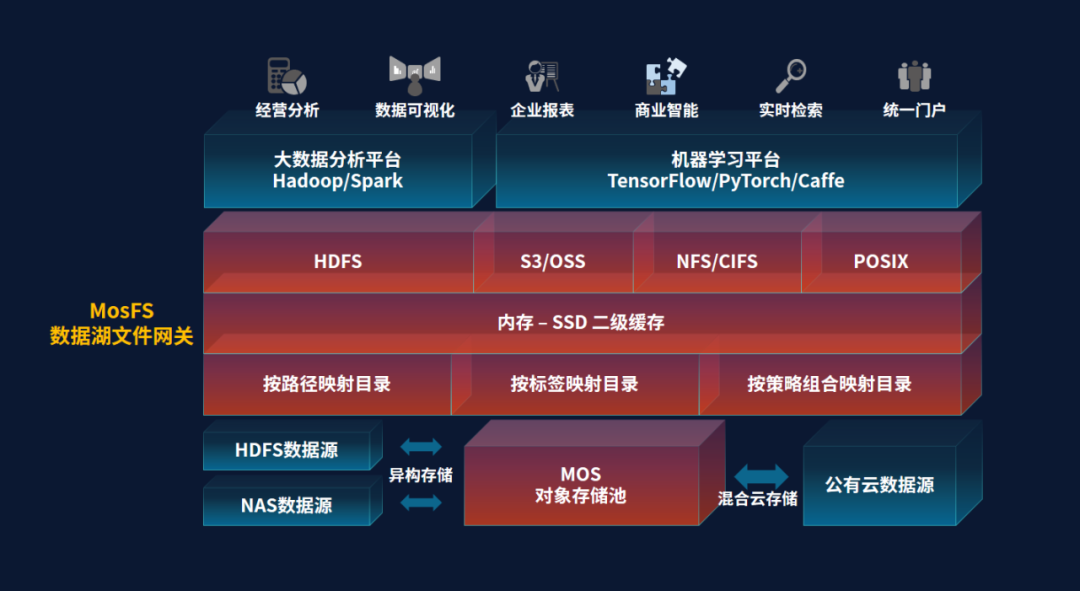
ͼ1�����ݺ��ļ����ؼܹ�
MOS����洢��MosFS�ļ�������Ϲ��������ݺ��ܹ�Ϊ��ҵͳһ�����ڶ������Դ��ʵ�ָ����ܴ洢�����������ṩ�˼�ʵ�Ļ�����
·��Ч�ʵĶ�����Դ����
MOS�����ɹܵ�������NAS�洢������洢��HDFS����Դ����ͨ��ӳ��ķ�ʽ���ϲ��ṩ���ݷ����������е�IT�ܹ���ʵ�ִ洢ϵͳ�Ŀ��ٸ�ӣ�����������Ǩ�ƿ����ں�̨�첽ִ�С�ͳһ���������ݿ���Ϊ����ƽ̨��Ӧ�÷�����Ҫ���ظ��ƣ����ٶԴ洢�ռ������
·���ݸ�֪�Ķ༶�������
����ѧϰƽ̨��ģ��ѵ����Ҫ�����ݵij����������ͳ����ӳ٣�MosFS���Ժ��ϲ�Ӧ��������ͨ����ǩ��֪��Ӧ�ù����ȸߵ����ݣ�����ѧϰƽ̨����ͨ��·�������ݱ�ǩ���������ϵȷ�ʽ�õ�����Ըߵ����ݼ�����ʵ�������У�MosFS����������ӳ���Ŀ¼����ͨ���ڴ��SSD�༶�������������ݷ��ʡ��������Զ���ʻ��ѵ���У��㷨��Ҫ���г����ڰ�����ij����ϲ������Ƶ��ͼƬ��MosFS�Ϳ���ͨ����Щ����������Ӧ�ı�ǩ����MOS�洢��Դ���е��������ӳ��Ϊһ��Ŀ¼����ͨ���༶�����ṩ��ѵ���㷨��
·���������ӳ�����
MosFS������ӳ������ʵ�������ݷ��ʵ����⻯����ͨ��ȫ�������ռ佫���ݳ��ָ��ϲ�Ӧ�ã�����ʱ�䡢��ǩ���ļ���ǰ�ȶ����Ȳ��Կ��Լ����ݵĹ�����
���ܱƽ�����ȫ����ķֲ�ʽ���ݺ��ļ�����
MosFS�ļ�������MOS����洢���Ժ���Ҳ���Է��벿��Ϊ���������ѧϰƽ̨�����������ͳ����ӳٵ�����Ҫ��ͨ����MosFS�ֲ�ʽ�����ڼ��������������������£�MosFS������������ı���Ԥ���ڴ��SSD���һ���ֲ�ʽ�Ļ�����Լ���ѵ������ͳ�ֲ�ʽNAS��Ϊ����ѧϰ��˴洢�ķ������гɱ��߰����������������ʹ洢���ܻ�ͨ��ȱ�㣬���ݹ����������ѵ��Ч�ʵ��£���ȶ���MosFS�ķ������Թ���MOS��ԭ��NAS��HDFS�洢��ͳһ����������ͼ���ҷֲ�ʽ���ݻ�����Խ�ѵ��Ч������������ܽӽ���ʹ�ü���������ı���SSD��
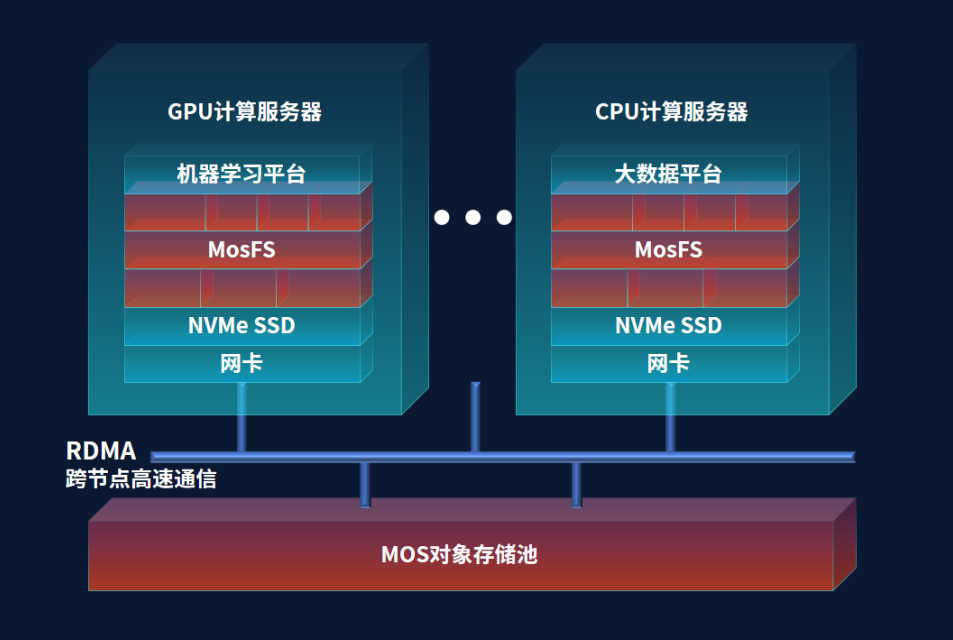
ͼ2�����ݺ��ļ����طֲ�ʽ�����ڼ��������
HDFSЭ����ǿʵ�ִ����ݴ������
HDFS��Ϊ��ͳ�����ݲֿ�洢ƽ̨�����ݺ��������������ܺͳɱ������⡣��ʵ��Ӧ���У���10��20PB���ϵ����ݹ�ģ�£�HDFS�������½����أ�����HDFS����ֻ֧�ֶั���Ĵ洢ģʽ���Ծ�ɾ���֧��Ч�����ѡ�MosFS��MOS��Ϲ��������ݺ��洢����HDFS�ӿں�S3Э�飬����ʵ�ִ洢��Hadoop����ƽ̨�ķ��룬�����ͻ���HDFS������ͳһ�鼯��MOS�洢�У�ʵ�ַǽṹ�����ݡ���ṹ�����ݺͽṹ�����ݵ�ͳһ������MosFS�ṩ��ԭ��HDFS�ӿ�100%��������ƽ̨�������ڲ�ʵ����S3/OSS��HDFS�ӿ�Э��Ļ�ͨת�����������ݶ�ο�����
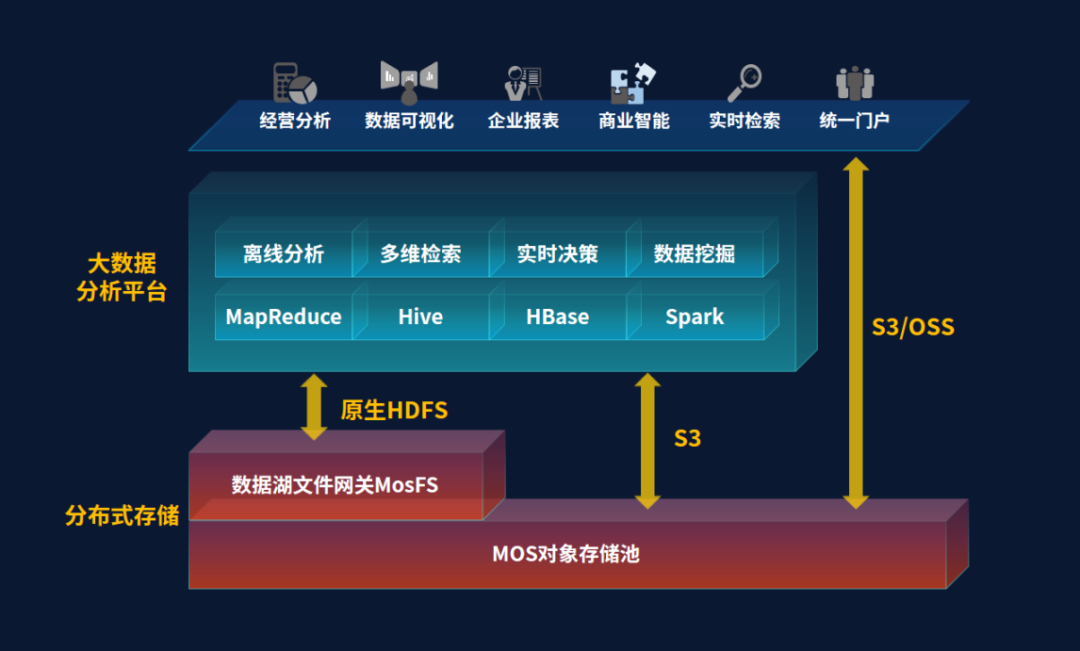
ͼ3�����ݺ��ܹ�ʵ�ִ������
�����ݷ�����AIѵ�������ںϵ�����Խ��Խ�࣬��ͳ�Ĵ����ݴ洢���ṩHDFS�ӿ�,�����ݷ����Ľ���������AIѵ������Ҫ�����ݿ����������洢�д������������ݷ�������Ч�ʵĵ��£�Ҳ�˷��˴洢�ռ䡣ɼ���������ݺ��ܹ������ṩHDFS�ӿ����ڴ����ݷ����������ṩ�ļ��Ͷ���ӿ�����AIѵ�������������ݷ��������ֱ��ͨ���ļ��ӿڷ��ʣ����追���͵ȴ����ܴ�̶����������ںϳ����Ĵ����ݷ���Ч�ʡ�
AIѵ��ʵ������
�������ܼ�����Ӧ�ù��ҹ���ʵ���������й��Ƽ���ѧ�齨�����п�Ժ��������ѧ�������ٶȵȻ�����ͬ�н��Ĺ��ҹ���ʵ���ң��п����Գ�����2017�꣬�Ǹ�ʵ���ҵIJ�ҵ��ƽ̨��ͨ���“�Ƚ��˹������㷨+���м�����+˽�в�����”�����ܻ����ƽ̨�������ṩ������Դ���˹����ܼ��������ܻ���������ȷ���
�п����Կ�����������OS�ṩ�˴��ģ���������ݺ����ܼ�������Ч�����˹����ܴ�ҵ�ż����ܹ��ٽ��˹�����Ӧ����̬�ķ�չ�����ܸ���ҵ�����������ת�͡�Ŀǰ��ƽ̨�Ѿ������180��AIǰ���㷨��100��ͨ�����ݼ����߱��ḻ��ƽ̨�������ҵ��ؾ��顣
ɼ���������ݺ��ܹ��Ѿ���������OS�õ�Ӧ�ã������п����Ե�ѵ�����������ݼ��ֱ���ڱ���SSD���ֲ�ʽNAS�洢��ɼ��MosFS+MOS�ϣ����ܶԱȲ��Խ��������MosFSѵ����ʱ�뱾��SSD�ӽ����Աȷֲ�ʽNAS��MosFS�ڵ�GPU�ڵ��¶�ȡ��������62.5%��˫GPU�ڵ�ֲ�ʽѵ������������75.8%����Ⱥ��ģԽ��ɼ�����ݺ�����������Խ�ܵõ����֣����ֳ����������չ�ԡ�
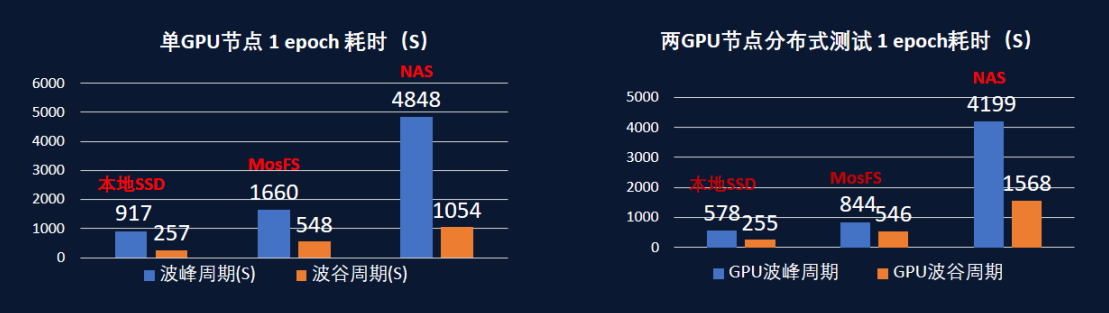
ͼ4������SSD��MosFS��NAS��ģ��ѵ�����ܶԱ�
С�����Ӧ�úʹ����ݷ�����Ҫ���ܵ��������ݺ�
���ݻ�����ʩ�����������ܺ��ںϡ����ݺ��������ʵ����Ч�����ݹ������ͻ���“��������”�����ܹ���Ҫ��洢�ṩ��ά�ȵļ����������������ڹ��������Լ����ݿ��ӻ�������ʵ�����ݵĺ������������������������ϴ��ת���������Ĺ��̡��洢�����ܹ�ʵ�ַ��룬�ṹ�����ݡ���ṹ�����ݡ��ǽṹ������ͳһ��������ݺ��У����������ݵ��������ݺ���ʵ���ںϣ���ͬ�������ݴ洢�Ľ�����ģ����
�˹����ܺʹ����ݷ���Ӧ�õ��ں�ʹ��һ�������ܹ�ͬʱ�ṩ��������㼰��������ʹ�ã���һ�����ݺ��洢ƽ̨����߱���Դ���ݹ�������������������������칹�ɹ������洢���������Լ������ܸ�֪���ݵĸ����ܶ�Э�����ݷ����������������ݺ��ܹ��ؽ�Ϊ���ݷ���������Ӧ�õĿ��������д�����ı������ӿ�����������̣�������ʩ�����ṩ�ۺϵ����ݷ����������������Ǹ�Ч�ʵ���ȡ���ݼ�ֵ��
|