NVIDIA Ampere架构内置TF32,能够加快单精度作业速度,保持精度且无需使用任何新代码。

与所有计算一样,你必须选择最佳的数值格式才能做好AI。由于深度学习是一个新兴领域,因此对于训练和推理需要哪种格式的数值,大家仍存在激烈的争论。
去年,我们讲解了各流行格式之间的差异,例如AI和高性能计算中使用的单精度、双精度、半精度、多精度和混合精度数学。如今,NVIDIA Ampere架构引入了一种新的方法,用于提高广泛用于AI的单精度模型的训练性能。
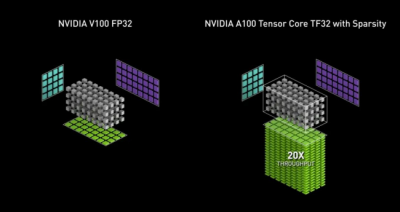
TensorFloat-32(TF32)是NVIDIA A100 GPU 中用于处理矩阵数学的新数值格式。矩阵数学也被称为张量运算,是AI和部分HPC应用主要使用的运算。与Volta GPU上的单精度浮点数值(FP32)相比,在A100 GPU Tensor核心上运行的TF32可提供高达10倍的加速。将TF32与A100上的结构稀疏性相结合后,相比于Volta可达到20倍性能提升。
认识新的数值
现在让我们先来了解TF32的工作原理和它的“用武之地”。
数值格式就像标尺。其指数位决定了它的范围和可以测量的对象大小。而它的精度则取决于其小数部分的尾数位,也就是底数或小数点后的浮点数。
一个好的格式必定是一个平衡的格式。它的位数既需要能够满足精度要求,同时也不能过多,否则就会减慢处理速度并造成内存膨胀。
下图显示的是TF32如何通过混合在张量运算中实现这种平衡。

TF32在性能、范围和精度上实现了平衡
TF32采用了与半精度(FP16)数学相同的10位尾数位精度,这样的精度水平远高于AI工作负载的精度要求,有足够的余量。同时,TF32采用了与FP32相同的8位指数位,能够支持与其相同的数字范围。
这样的组合使TF32成为了代替FP32,进行单精度数学运算的绝佳替代品,尤其是用于大量的乘积累加运算,其是深度学习和许多HPC应用的核心。
借助于NVIDIA库,用户无需修改代码,即可使其应用程序充分发挥TF32的各种优势。TF32 Tensor Core根据FP32的输入进行运算,并生成FP32格式的结果。目前,其他非矩阵运算仍然使用FP32。
为获得最佳性能,A100还具有经过增强的16位数学功能。它以两倍于TF32的速度支持FP16和Bfloat16(BF16)。利用自动混合精度,用户只需几行代码就可以将性能再提高2倍。
TF32的累累硕果
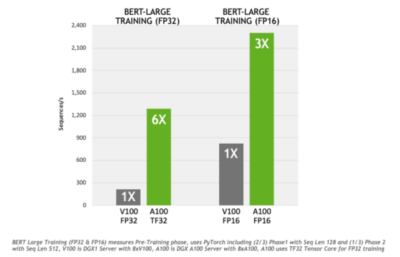
与FP32相比,TF32训练BERT的速度提高了6倍,而BERT是当今要求最高的对话式AI模型之一。其他依赖矩阵数学的AI训练和HPC应用上的应用级结果将因工作负载而异。
为验证TF32的精度,我们使用它训练了大量的AI网络,包括计算机视觉、自然语言处理和推荐系统等各种应用。结果显示,它们都具有与FP32相同的收敛到某一精度的行为。
而这正是NVIDIA将TF32设置为cuDNN库的默认数值格式的原因,cuDNN库可以加速神经网络上的关键数学运算。同时,NVIDIA正在与开发AI框架的开源社区合作,致力于使TF32成为A100 GPU上的默认训练模式。
今年6月份,开发人员将可以在NGC的NVIDIA GPU加速软件列表中获取支持 TF32 的Tensorflow版本和Pytorch 版本。
TensorFlow产品管理总监Kemal El Moujahid表示:“TensorFloat-32为AI应用提供了触手可及的训练与推理的大幅性能提升,同时又保持了FP32的精度。”
他还补充道:“我们计划在TensorFlow中提供TensorFloat-32原生支持,以使数据科学家无需修改任何代码,就可以利用NVIDIA A100 Tensor Core GPU获得大幅度的性能提升,从中受益。”
PyTorch团队发言人表示:“机器学习研究人员、数据科学家和工程师希望加快解决方案的实现时间。当TF32与PyTorch实现本机集成时,可使用基于NVIDIA Ampere架构GPU快速实现加速,而且无需更改任何代码,同时还能保持FP32的精度。”
TF32 加速HPC线性求解器
线性求解器是HPC应用的一种,使用重复矩阵数学计算的算法,其也将从TF32中受益。此类应用被广泛用于地球科学、流体动力学、医疗、材料科学和核能以及石油和天然气勘探等领域。
30多年来,全球都在使用运用FP32达到FP64精度的线性求解器。去年,一项针对国际热核实验堆的聚变反应研究表明,混合精度技术使用NVIDIA FP16 Tensor Core核心使此类求解器的速度增至3.5倍。在该研究中,这项技术还使Summit超级计算机的HPL-AI基准性能增至3倍。
为证明TF32为线性系统求解器所带来的强大功能和鲁棒性,我们在SuiteSparse矩阵集合中使用cuSOLVER(位于A100上的CUDA 11.0中)运行各种测试。在测试中,与包含FP16和BF16的其他tensor-core核心模式相比,TF32能够提供最快、最可靠的结果。
除线性求解器之外,其他高性能计算领域也使用FP32矩阵运算。NVIDIA计划与业内合作,研究如何将TF32应用于目前依赖FP32的更多用例。
|