AI芯片的竞争早已不是简单的峰值算力比拼,架构创新、软硬件的结合、芯片利用率(芯片实测算力/芯片峰值算力)越来越多的被关注。2020年6月23日,鲲云科技发布了全球首款量产数据流AI芯片CAISA,定位高性能AI推理。据悉,CAISA最高可实现95.4%的芯片利用率,较同类芯片提升最高11.6倍。第三方测试数据显示仅用1/3的峰值算力,CAISA芯片可以实现英伟达T4最高3.91倍的实测性能。数据流芯片为什么能实现超高利用率?CAISA在哪些领域优势明显?

鲲云科技创始人牛昕宇
什么是数据流芯片?
相比数据流芯片,冯诺依曼架构的芯片更被大部分人所熟知,CPU就是冯诺依曼架构的代表。不过,由于冯诺依曼架构是通过指令执行次序控制计算顺序,并通过分离数据搬运与数据计算提供计算通用性。凭借其通用性和广泛的应用,冯诺依曼架构芯片成为了重要的AI芯片。
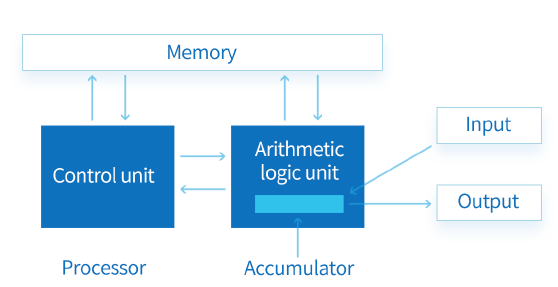
基于冯诺依曼的典型指令集架构示意图
但是,随着AI算法的不断演进,AI模型对算力的需求不断提升,内存性能跟不上计算单元算力的迅速提升,冯诺依曼架构的内存墙问题成了阻碍AI和AI芯片发展的关键。打破内存墙瓶颈成为关键,可重构、存算一体等创新的架构受到越来越多的关注,数据流芯片也是其中之一。
与冯诺依曼架构芯片不同,数据流芯片是依托数据流流动次序控制计算次序,采用计算流和数据流重叠运行方式消除空闲计算单元,并采用动态配置方式保证对于人工智能算法的通用支持,突破指令集技术对于芯片算力的限制。目前,全球基于数据流方式研究AI芯片的并不多,主要是鲲云、Wave Computing、Sambanova、Groq。
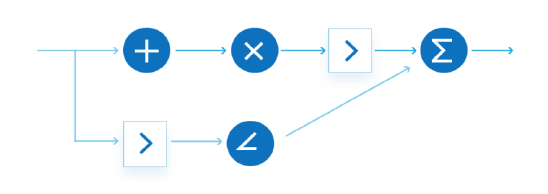
定制数据流计算示意图
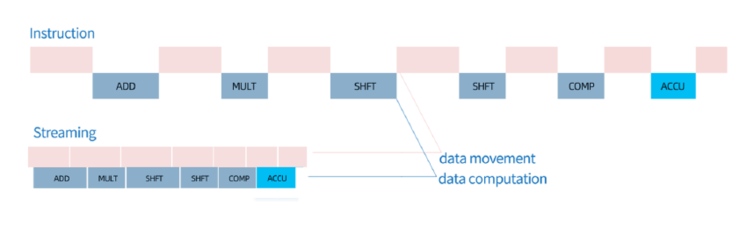
指令集架构与数据流架构在数据流动和计算顺序上的区别
全球推出量产数据流AI芯片的目前只有鲲云。以鲲云的CAISA架构为例,数据流架实现AI计算有三大核心挑战:
高算力性价比:要在保持计算正确前提下,通过不断压缩每个空闲时钟推高芯片实测性能以接近芯片物理极限,让芯片内的每个时钟、每个计算单元都在执行有效计算;
高架构通用性:要在保证每个算法在数据流芯片上运行能够实现高芯片利用率的同时,支持所有主流CNN算法;
高软件易用性:要让用户无需底层数据流架构背景知识,简单几步即可实现算法迁移和部署,降低使用门槛。
数据流芯片如何实现最高95.4%的芯片利用率?
鲲云CAISA3.0架构在这三大技术上都有突破。实现高算力性价比的关键是时钟级准确的计算,这也是数据流架构芯片的核心挑战。
鲲云科技创始人牛昕宇对雷锋网表示:“时钟级准确的计算是数据流本身核心开发的挑战,在架构设计的第一天脑海中就要有一个时钟精确的概念。不止是架构要时钟精确,软件要时钟精确,开发的模型也要时钟精确。要做到这一点其实很难,今天我们跟大家说为什么鲲云迭代了三代架构,这里面每一个挑战都需要大量工程积累,不断的迭代来做到时钟精确。”
具体而言,CAISA3.0架构通过数据计算与数据流动的重叠,压缩计算资源的每一个空闲时钟;通过算力资源的动态平衡,消除流水线的性能瓶颈;通过数据流的时空映射,最大化复用芯片内的数据流带宽,减少对外部存储带宽的需求。
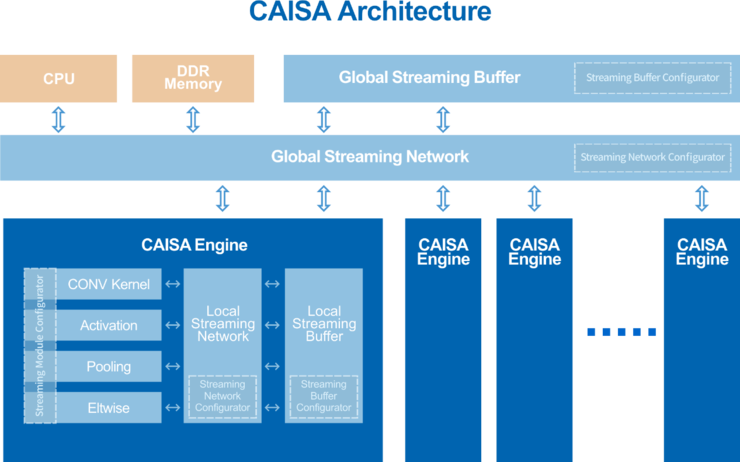
CAISA3.0架构
这样的设计使CNN算法的计算数据在CAISA3.0内可以实现不间断的持续运算,最高可实现95.4%的芯片利用率,在同等峰值算力条件下,可获得相对于GPU 3倍以上的实测算力,提供更高的算力性价比。
除了高性能,面对复杂多样的AI需求,AI芯片的通用性也决定着AI芯片能否更广泛被应用。据悉,CAISA3.0架构可以通过流水线动态重组实现对不同深度学习算法的高性能支持。通过CAISA架构层的数据流引擎、全局数据流网、全局数据流缓存,以及数据流引擎内部的人工智能算子模块、局部数据流网、局部数据流缓存的分层设计,在数据流配置器控制下,CAISA架构中的数据流连接关系和运行状态都可以被自动化动态配置,从而生成面向不同AI算法的高性能定制化流水线。
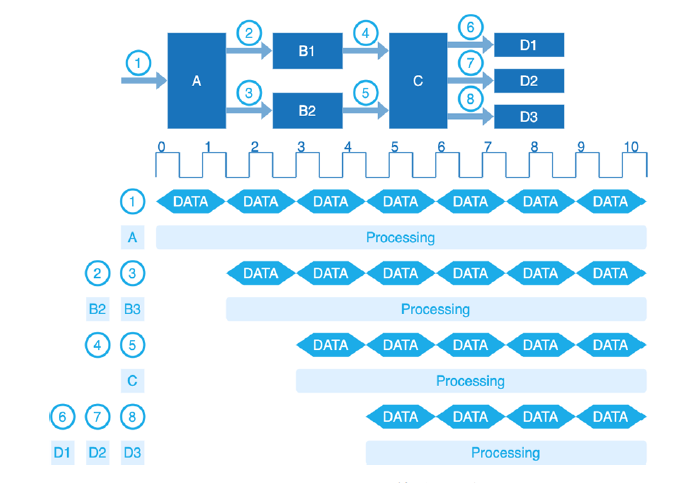
数据流动与数据计算重叠示意图
说的简单一些,借助数据流配置器,CAISA架构可以根据不同的AI算法定制适合的流水线,去满足目标检测、分类及语义分割等的需求。另外需要补充的是,数据流架构中数据和计算是融合在一起,数据通过PCIe接口输入,芯片内有少量缓存单元,在两个数据流连接不是那么完美的时候,起到缓存作用。
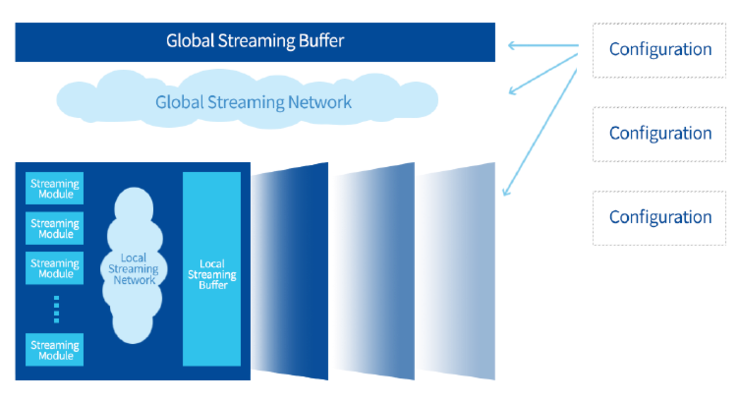
CAISA架构中资源配置示意图
“至于对新算法的支持,我们一方面通过软件工具不断迭代,另外CAISA架构也会持续迭代。CAISA支持的8GB DDR能满足多种算法的组合和存储,我们考虑了AI长期的发展。”牛昕宇表示。
软件不仅有助于满足不断更新算法的需求,其易用性还是吸引客户的关键。据了解,鲲云专为CAISA3.0架构配备的RainBuilder编译工具链支持从算法到芯片的端到端自动化部署,无需了解架构的底层硬件配置,简单两步即可实现算法快速迁移和部署。
鲲云科技合伙人兼研发总监熊超表示“我们支持开发中常用的语言,C、C++、Python接口都提供。在使用方式上,RainBuilder也跟现有市面上比较常见的工具链相似。绝大多数情况下,用户通过代码上较小的改动就可以将算法切换到鲲云的加速卡上运行。虽然我们底层是数据流架构芯片,但是从使用上来将架构的不同对用户来说是感知不到的。”
当然,RainBuilder编译器还可自动提取主流AI开发框架(TensorFlow,Caffe,Pytorch,ONNX等)中开发的深度学习算法的网络结构和参数信息,并面向CAISA结构进行优化。
鲲云科技合伙人兼COO 王少军博士对雷锋网表示:“通过主流开发框架开发出的模型通过编译器部署到CAISA这个过程是自动化的,只需要跑一个脚本,目前实测的客户包括已经部署的客户效率都非常高。当然,我们不排除第一次部署过程中软件的兼容性或者其他方式会有一些问题。”
CAISA对标英伟达边缘端旗舰产品
接下来关键的问题是,CAISA实际表现如何。鲲云此次发布的CAISA AI芯片采用英特尔28nm工艺,搭载了四个CAISA 3.0引擎,有超过1.6万个MAC(乘累加)单元,峰值性能可达10.9TOPs。通过PCIe 3.0×4接口与主处理器通信,同时具有双DDR通道,可为每个CAISA引擎提供超过340Gbps的带宽。

基于CAISA 芯片,鲲云推出了星空系列边缘和数据中心计算平台,X3加速卡和X9加速卡。星空X3加速卡为工业级半高半长单槽规格的PCIe板卡可以与不同类型的计算机设备进行适配,包括个人电脑、工业计算机、网络视频录像机、工作站、服务器。

相较于英伟达边缘端旗舰产品Xavier,X3可实现1.48-4.12倍的实测性能提升。
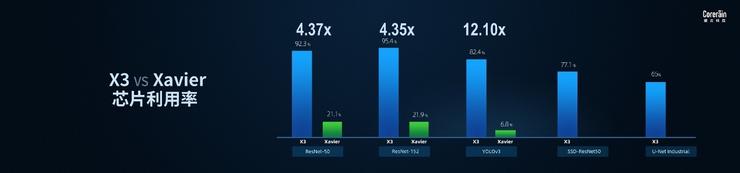
X3 vs Xavier 芯片利用率对比图
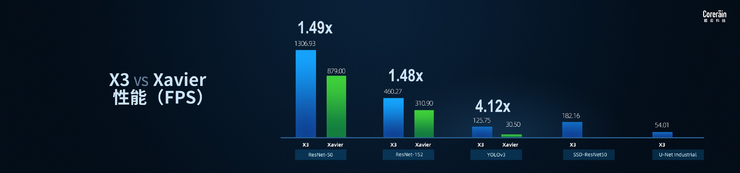
X3 vs Xavier 性能对比图

X3 vs Xavier 延时对比图
星空X9加速卡定位比星空X3更高,搭载4颗CAISA 芯片,峰值性能43.6TOPS,对标的也是英伟达AI加速卡T4。
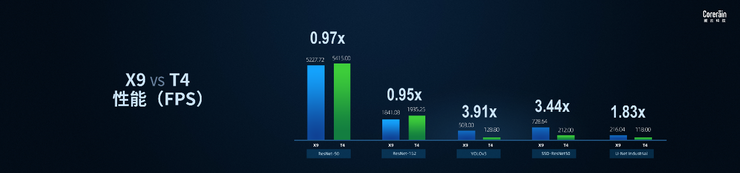
根据第三方评测机构给出的实测性能,X9在ResNet50可达5240FPS,与T4性能接近,在YOLO v3、UNet Industrial等检测分割网络,实测性能相较T4有1.83-3.91倍性能提升。在达到最优实测性能下,X9处理延时相比于T4降低1.83-32倍。
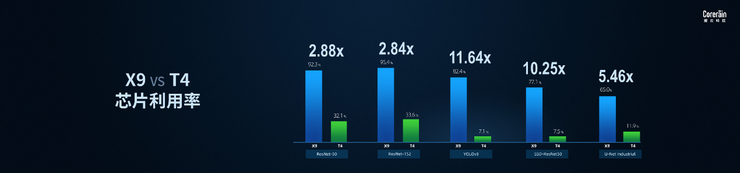
X9 vs T4 芯片利用率对比图
X9 vs T4 性能对比图

X9 vs T4 延时对比图
整体而言,凭借CAISA数据流架构的高芯片利用率,实现的实测性能,对芯片峰值算力的要求可大幅降低3-10倍,这可以进一步降低芯片制造成本。目前星空X3加速卡已经实现量产,星空X9加速卡将于今年8月推出。
目前,星空加速卡已在电力、教育、航空航天、智能制造、智慧城市等领域落地。王少君说:“我们的低延时优势确实比较明显,尤其是工业和自动驾驶行业里,我们的各种客户都给我们反馈了同样的信息。当然,作为一家初创公司,软件生态是我们需要去努力的方向。”
|








