��Ӧ�ó������������Ժ��ܻ����CPUռ���ʹ��ߣ�I/O�������½����������⣬��ʱ������Ҫ�Գ�������Ż������ܵ�����һ���Ƚϸ��ӵĹ��̣�������������ѹ�����ԡ�ȷ��ƿ����ʵʩ�Ż���ȷ���Ż���5�����衣���Ź��̶Գ���Ա��֪ʶ�ṹҪ��dz��ߣ���Ҫ�dz���ϤӲ��������ϵͳ(OS\JVM)��Ӧ�ó���ȶ�����档
���ߣ����Ć�
����920������(����ARM�ܹ�)���������˼·����ͨ��“���”���ǿ�����ܡ����и���ĺ�����2NUMA/Socket��L3 CachelineΪ128 Byte����Щ����оƬ��һЩ���ԣ���Щ���Զ������ܵ���Ҳ�������ͬ��Ӱ�졣
1��11�գ���Ϊ������������ɳ��-����վ�����Ի�Ϊ����λ����ר�ҷ������ĸ����⣬�ֱ���—�������������������ܵ���;�����������Ż�ʵ��;A-Tune�Ե��ż������;iSulad�������������ʵ��������������������ž������ܴ�һ�ӭ���ֳ����뻷�ڡ���Ϊ����ר���ֳ���ʾ��ָ�������߽���ʵ�١�

�λ����Ǻ�Ӱ����
���������������ܵ���˼·
��һλ�����α��ǣ���Ϊ���ܼ��������ʦ���֡���ָ�����ܵ�����һ�����ڵĹ��̣����鿪������ѡ��һ�����������ܵ���ƽ��㣬ֻ������ʵIJ��ܴﵽ��õ����ܡ���������������˵��������Ӱ��Ƚϴ���������ԣ���һ����NUMA�ܹ����ڶ�����L3 Cacheline��
����������֧��NUMA�ܹ���ͨ���ʵ������ܵ��ţ����ܹ���ɺܺõ����ܣ����ܹ����SMP�ܹ��µ�����ƿ�����⣬�ṩ��ǿ�Ķ����չ�������Լ����ø����ļ���������
ע��Cachelineα����������920��x86��Cacheline��С��һ�£����ܻ������X86���Ż��õij��������� 920 ������ʱ������ƫ�͵��������Ҫ������ҵ����������ڴ�����С��X86 L3 Cacheline��СΪ64�ֽڣ�����920��CachelineΪ128�ֽڡ�

��Ϊ���ܼ��������ʦ ����
����������֧��NUMA(Non-uniform memory access�� ��ͳһ�ڴ����)�ܹ����ܹ��ܺõĽ��SMP������CPU��������Լ��NUMA�ܹ�������˽��һ���ڵ� (Node)��ÿһ���ڵ��൱����һ���Գƶദ����(SMP)��һ��CPU�Ľڵ�֮��ͨ��On-chip NetworkͨѶ����ͬ��CPU֮�����Hydra Interfaceʵ�ָߴ�����ʱ�ӵ�Ƭ��ͨѶ����NUMA�ܹ��£������ڴ�ռ����������Ƿֲ�ʽ�ģ�������Щ�ڴ�ļ��Ͼ�������ϵͳ��ȫ���ڴ档ÿ���˷����ڴ��ʱ��ȡ�����ڴ�����ڴ�������λ�ã����ʱ����ڴ�(���ڵ���)�����һЩ��
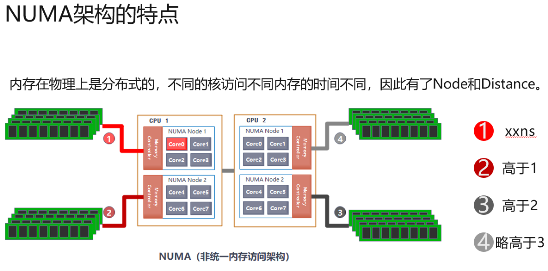
NUMA�ܹ����ص�
���Կ�����ͬNUMA�ڵ�CPU core����ͬһ��λ�õ��ڴ棬���ܲ�ͬ���ڴ������ʱ�Ӹߵ���Ϊ����CPU > ��NUMA����CPU > NUMA�ڣ������Ӧ�ó�������ʱҪ�����ܵı����NUMA�����ڴ棬����ͨ�������̵߳� CPU������ʵ�֡�

NUMA���÷���
CPU���ڴ桢�������������ĸ�ģ�飬ϵͳ��Ϊ�����ṩ��һЩ���߽������ܷ�����
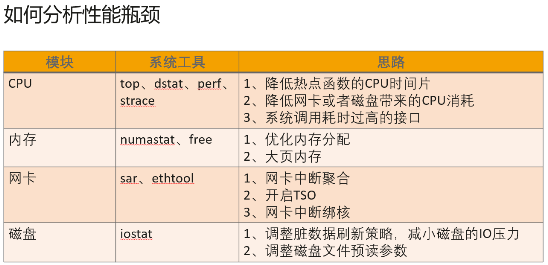
ϵͳ��ƿ���ж�
�����������Ż�ʵ��
�ڶ�λ�����α��ǣ���Ϊ���������ݽ������������ʦ����˶�塣�������ǽ��������������ݵ�������̬��������Դ������ƽ̨Ambari+HDP�������ֲ���顣������������������(Kunpeng Developer Kit)��ʵ�ֶԺ���������п���ɨ��ͷ��������ṩרҵ�Ĵ�����ֲָ�����Լ���ֲ��ȫ���ϵͳ���ܷ�������ӻ����֣��Ӷ���������������������ֲ�����Ч�ʡ�

��Ϊ���������ݽ������������ʦ ��˶��
����ͼ���Կ�����������������̬�dz����ƣ��ڴ��������������涼����һ����֧�֣�Ӳ�����֣�̩ɽ�ṩ��TaiShan 2280 100/200�ͷ�������оƬ��������916��920оƬ�ɹ�ѡ��ͨ��24�ˡ�32�ˡ�48�ˡ�64����������ҵ�Բ�ͬ������Ҫ���������������Դ�����Դͷ�����ݴ������洢���ܹ�����֧�֡���ǰ֧�ֵĴ�����ƽ̨�л�ΪFusionlnsight������Ambari���������ţ����ǣ����ǽ�Ϊ�����ݿ�����ֲ������ƽ̨�����ṩ֧�֡�

���������ݽ������
Ϊ�˽���Դ������ƽ̨Ambari+HDP�����ֲ��̩ɽ������Ҫ��ֲʲô����?��һ����Jar������ЩJar������So����Ҫ������ƽ̨���±��롣���������So�ļ�����Ҫ���±��롣����ǿ�ִ�ж������ļ��������ײ��оƬ�ܹ�����Ҫ���±��롣�����Ϊ�ĸ����裺
��RPM�����࣬��ΪX86_64��Noarch��������
ʹ��checkSo����ɨ��RPM
����RPM������ѯ�ó��ó���װ��Ҫ��������������ѹ��ȡrpm��Դ�ļ��������ӣ����/var/lib�ȹؼ�Ŀ¼���ԱȰ�װǰ��������Դ�ļ��������ӡ�
����RPM��

��Դ������ƽ̨Ambari+HDP�����ֲ�����ܽ�
A-Tune�Ե��ż������
����λ�����α��ǣ���Ϊ2012ʵ���Ҹ�����ʦл־�������ܵ��Ŵ�����ʱ��ͳɱ���֧��������ʦ������Ҫ����Թ����ҵ�ƿ���㣬�����˹�Ѳ����ҹ���ԭ��װ���ּ�ع��ߣ����ܷ�����ʮ�����ݣ��ڼ����Ҫ������������ʦ���ܵ�ʱ�䣬�ŵ�������ϵͳ���ܡ�

��Ϊ2012ʵ���Ҹ�����ʦ л־��
��ʹ����ʵ���ҵĵ��Ŵﵽ��Ԥ�ڵ�Ч��������������ҵ��������ʵ�������棬ҵ���ض��ǻᶯ̬�仯��������ʦ�ĵ��Ź�����������ֻ��Ӧ�Ծ�̬���س��������ڶ�̬���س��������ߡ�
��ǰϵͳ���ŵ�����ʹ���ǣ�
���ʹ����ϵͳ��֪�ϲ�ҵ��
��ν����˹����ųɱ�
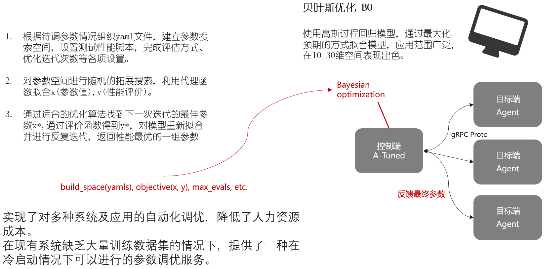
����openEuler���Ե���ϵͳA-Tune��ʹ��ϵͳ����������ʶ��ҵ��ƥ�������Դģ�ͣ�ʵʱ��Ӧҵ�������仯��Ŀǰ��ϵͳ�������������ؼ������㡣��һ���Ǹ�֪��������ôȥ����ϵͳ����?��Ҫ��ͨ�����ࡢ�������ϵķ������ֱ���CPU��IO�����硢�ڴ淽�����Ȼ��ͨ��һЩ�����ҵ�����һЩϸ���ķ��࣬���ﵽ��ʶ��ҵ���Ч����
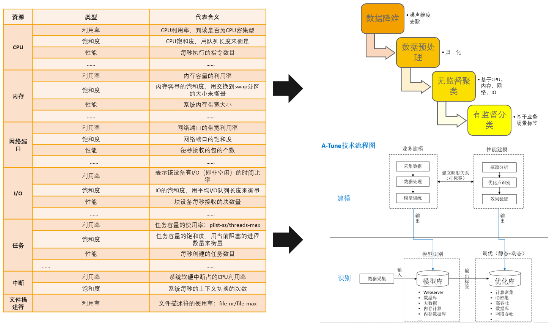
ϵͳ�������֪����
�ڶ����ؼ������㣬���ڻ���ѧϰ�㷨�ĵ��Ų��������������ڻ���ѧϰ����ı�Ҷ˹�Ż��㷨ȥ����һ�����Ų������Զ���������������ʦֻ��Ҫ�ṩһ������Ϊ������ҵ��������Ӱ��IJ������Լ�������Χ��������������Щ�����Ͳ�����Χ�������ǵĻ���ѧϰ�㷨�����Ҹ�������ָ�ꡣ
iSulad�ķ�����ʵ��
����λ�����α��ǣ���ΪiSula�����ŶӼܹ�ʦ��尕F������Sysdig��2019�������ʹ�ñ��桷��ʾ���������ܶȷ��棬��2018����ȣ�ÿ̨�����е������ܶ������100%����15�����ӵ���30���������ڵ��ܶ��Ѿ��ﵽ��250������Ե�ڵ���Դ���У��������������������Դ��ָ������һ���������������ٵ����������֮������

��ΪiSula�����ŶӼܹ�ʦ ��尕F
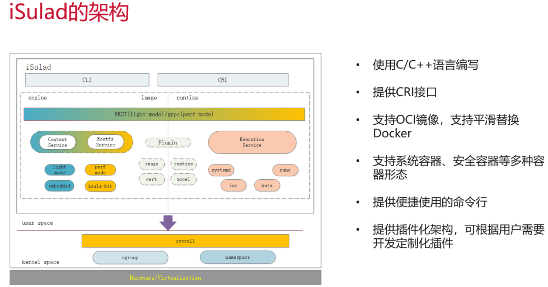
iSulaΪȫ������������ջ���������桢���硢�洢������������OS;iSulad ��Ϊ�������������������棬����Ϊ���ֳ����ṩ�������ȶ����ȫ�ĵײ�֧�ţ�Ŀǰ�ѿ�Դ�����ʹ�á���Դ��ַ��https://gitee.com/openeuler/iSulad
iSulad�����ᡢ�졢�ס����ĸ��ص㣺
�iSulad�ĵ�һ��ʹ�ó������ڶ˲��豸�ϣ���һ����������ͷ��ʹ���������ﵽ���١����л��㷨Ӧ�ò���Ĺ���
�죺����C/C++����ʵ�֣��߱������ٶȿ졢����͵����ԣ���LXC����ʱ����IJ������ҲΪiSulad���������ṩ�˻�ʯ
�ף�iSuladΪ��ʹ������Ǩ�Ʒ��㣬���ڳﱸ����һϵ��Ǩ�ƹ��ߣ����������߽��Լ���Ӧ��ƽ��Ǩ�Ƶ�iSulad����
�飺��Բ�ͬ��ʹ�ó����ṩ��ͬ��ģʽ���������л��������߿��Ը����Լ���ʹ����Ҫ��������л�ע�����ܵ�performanceģʽ��ע����Դռ�õ�lightģʽ
iSulad�ļܹ�
���ҵĵ���ʵ��
���ĵ���ʵ���ϻ������������ҵģ��������ǹ�Ȼӵ������ʵ�ļ���������ÿһλָ����ʦ���Զ�Χ����һȺ�����ߣ���ϵͳ���á�����˼·�������Ż������Ϸ�����ÿһλ�����߶�������Ũ��ļ���̽�ַ�Χ�У�����Ҳ�ɷ��˼�λ�����ߡ�

Ũ��ļ���̽�ַ�Χ
Q1������������μӵ�ʵ������?�о�����ɳ������ʵ����ô��?
A���μ���iSula�����������̸о����ܺá�ʵ�����ںܺÿ������������������ϸ��ܵ������Ʒ��ô����ǰ�������۽������������Ͼ���ʹ���ǿ��ü������ŵģ�����dz��á�
Q2���Ժ�ϣ����������������ɳ���������ݷ�������?
A������Ӧ��ָ���Ը�ǿ�����ݣ���Ϊ���ڹ������õ��������������������о�ϵͳ����IJ��ź��о������ݵIJ��ţ���������Ӧ��ϵͳ����������⣬�����ܻ�������õ�Ч��������Ӧ��ָ����Ҳ���ǿ��

���ҵı���ʵ������
|