
OpenAI 的 GPT-2曾经掀起的「大规模语言模型到底水平多高、到底有没有危害」的口水仗慢慢冷下去了,而语言模型的实用性问题也越来越展现出来:如果很难控制一个语言模型的输出,那可能就很难找到它的实际应用,只能沦为刷分工具。
近期,Uber AI 研究院的一篇论文《Plug and Play Language Models: A Simple Approach To Controlled Text Generation》(https://arxiv.org/abs/1912.02164)中介绍了一种简单、高效的精细控制方法,可以轻松地让大规模语言模型生成指定的主题、风格的文本,而且还有很广泛的适用性。Uber AI 的研究人员们把它比喻为「让小老鼠控制一只猛犸象」。雷锋网(公众号:雷锋网) AI 科技评论把论文的解读博客编译如下。

一个实际的挑战:基于预训练模型的条件文本生成
2017年谷歌提出的基于注意力的 Transformer 网络架构为自然语言处理开辟了一个全新的时代。从此之后,基于 Transformer 改进的更大、更大的模型层出不穷,基于深度学习的自然语言处理方法也在各种各样的任务中取得越来越好的成绩。
随着 BERT、GPT-2 之类的大规模语言模型出现,NLP 研究者们通过实验表明了只需要用简单的目标函数在超大规模的无标注语料上训练,得到的语言模型就可以在语言建模任务(给定一组开头以后向后续写)中得到前所未有的流畅度,文本的自然、合理程度可以接近人类水平。
比如,给定一个开头「这里的食物不好吃」,一个语言模型(比如 GPT-2)能续写成这样的看上去相当合理的一段话「这里的食物不好吃,店员又懒又粗鲁。这食物真让人喜欢不起来,即便我的要求一点也不高。」
不过,虽然这些模型生成的句子体现出了拼写、语法、语言习惯等等复杂的语言知识,但想要具体地控制模型生成的内容仍然非常困难。换句话说,虽然模型有能力生成各种各样不同的句子,或者为一个给定的开头续写出很多不同的段落,但我们很难指定让模型生成某一种风格的、某一种话题的、某一种叙述逻辑的文字。比如,同样是以开头「这里的食物不好吃」进行续写,人类可以欲扬先抑,最后得到一个正面的结论,也可以挂羊头卖狗肉,话说到一半慢慢从讲食物变成讲政治的。想让语言模型做到这些就非常困难。
在这篇论文里,Uber AI 的研究人员们在这个问题上做出了一些突破。我们先看一个例子,他们用他们的方法要求模型生成一段正面的续写,效果是:「这里的食物很糟糕,但还有音乐、故事和魔力!Avenged Sevenfold 的摇滚音乐剧演得太精彩,以后在全世界都能看到。」文本表达的情感从负面转变成了正面,但还是挺连贯自然的。
在此之前,全世界的 NLP 研究人员们提出过各种各样的条件文本生成方式,包括,1.从一个预训练语言模型开始,做精细调节,以便让它始终都能生成某种特定风格的句子;2.从零开始训练一个大型条件生成模型;3.不改变这个大的语言模型,而是通过关键 n 元组替换的方式,调节已经生成的句子的风格。
Uber AI 这篇论文带来了一种全新的有控制的文本生成方式,他们称之为「the Plug and Play Language Model」(即插即用语言模型,PPLM)。通过 PPLM,用户可以向大型非条件性的生成模型中灵活地插入一个或多个属性模型,这些插入的模型可以代表不同的想要控制的属性。PPLM 的最大优点是不需要对语言模型做任何额外的改动(不需要重新训练或者精细调节),就让资源不足的研究人员也可以直接在预训练语言模型的基础上生成条件文本。
如何驾驭一头猛犸象
NLP 研究人员们目前开发的最大的、语言能力最强的语言模型都非常大,动辄有数十亿的参数,训练它们需要大量的计算资源(从零训练一个模型,租算力大概需要六万美元),而且训练这些模型还需要海量的文本数据,即便模型的代码是开源的,这些训练数据也通常不是开源的。在许多意义上,大规模语言模型就像猛犸象一样,它们聪明、有力,但是它们的行动又随意又笨重。
这样的语言模型带来的结果就是,除了那些有最充沛的资源和资金的研究人员之外,其它的研究人员和开发者都只能在无论如何都不理想的情境中三选一:1.直接使用公开的预训练模型(虽然有好的语言建模能力但无法完全匹配他们的需求);2.在小一些的数据集上对预训练模型做精细调节(但一旦出现灾难性遗忘,就会让模型的表现大幅下降);3.需求不符只能从零训练新模型,但预算有限,只能训练小得多的模型(表现也自然也会有明显差距)。
Uber AI 提出的 PPLM 就能在这样的困境面前起到很大帮助,需要符合自己需求、且表现优秀的语言模型的研究者和开发者,不再需要想办法训练自己的模型,只需要用几个小的属性模型控制大预训练模型的生成,就可以达到目标。一个属性模型可以只有预训练模型的百万分之一大,同时仍然有很强的引导能力,就像在猛犸象的头顶坐了一只小老鼠,就能够灵活地控制让猛犸象往哪里走。
控制一个语言模型的不成功方法
语言模型有几类,对应几种不同的分布。
首先有非条件性的语言模型,它的分布是 p(x),是所有文本上的一个概率分布。GPT-2 之类的非条件性的语言模型就是建模了这样的分布。这样的语言模型是通用的,可以为许多不同种类的话题生成流畅的文本。
其次,条件性语言模型的分布是 p(x|a),这就是我们的目标。在给定某种属性 a 之后,这种假想模型就可以生成带有这种属性的文本。
接下来,属性模型的分布是 p(a|x),它是根据给定的句子输入 x 计算句子带有属性 a 的概率。比如,经过属性模型计算,某个句子有10% 的可能性是正面情绪的,以及有85% 的可能性是关于政治的。属性模型可以很小、很容易训练,仅从直观上来看,判断某个句子是否含有某种属性就是个分类任务,要比写出这样的句子简单得多;尤其是,如果在语言模型学习的语言表征上训练这样的属性(识别)模型,OpenAI 的论文《Improving Language Understanding by Generative Pre-Training》就已经表明了可以轻松地训练一个表现优秀的小模型。在 Uber AI 的实验中,一个单层的、4000 个参数的属性模型就能在属性识别和文本生成引导中发挥很好的效果。
那么我们想要的条件性语言模型,也就是 p(x|a) 从哪里来呢?幸运的是,根据贝叶斯法则,这个模型可以用第一个和第三个模型表示出来,也就是:
p(x|a) ∝ p(a|x) p(x)
不过,虽然这种方式让我们可以方便地计算概率(「这个句子符不符合我们想要的样子」),但我们很难从这种表达中采样。我们可以先尝试常见的拒绝采样或者重要性采样,从 p(x) 分布开始逐一采样筛选—— 这种做法理论上可行,但实际操作起来,要么会得到有偏倚的结果,要么运行速度非常慢。想用这种方式生成一个谈政治的句子,大概会是这样的状况:
从 p(x) 中采样得到一个句子 x
把句子 x 输入 p(a|x) 计算它是否是关于政治的
如果不是,重复第一步
显然,这就是从随机生成的句子里把关于政治的句子挑出来而已,由于 p(x) 覆盖了大量不同的话题,运气不好的话可能很久都无法得到关于政治的句子。对于越长的句子,生成满足要求的整句话也越难(需要越好的运气),花费的时间会指数级增加。这简直像「无数多的猴子在无数多的打字机上随机地打字,并持续无限长的时间,那么在某个时候他们必然会打出莎士比亚的诗集」,理论上正确,但无法用在实践中。
用梯度控制大规模语言模型
PPLM 解决这个问题的方式是,他们用属性模型通过梯度控制大语言模型。他们逼近实现了 1996 年的论文《Exponential convergence of Langevin distributions and their discrete approximations》中的更高效的 Metropolis-adjusted Langevin 采样器,而且参考了 Plug-and-Play Generative Networks (PPGN,arxiv.org/abs/1612.00005)中在一对神经网络上的实现方式。这样一来,PPLM 生成一个样本就变成了这样的简单的三步:
给定一个部分生成的句子,计算 log(p(x)) 、log(p(a|x)),以及两者关于语言模型的隐层表征的梯度。只需要对属性模型和语言模型都做一次高效的前馈传播和反馈传播,这几个值都可以计算出来。
根据计算出的梯度,在反馈传播中,根据属性模型的梯度更新语言模型的隐层表征,向着增加 log(p(a|x)) 和 log(p(x)) 的方向移动一小步,也就是增加了生成的文本带有想要的属性的概率
由于上一步更新,语言模型的分布被改变,然后采样一个词
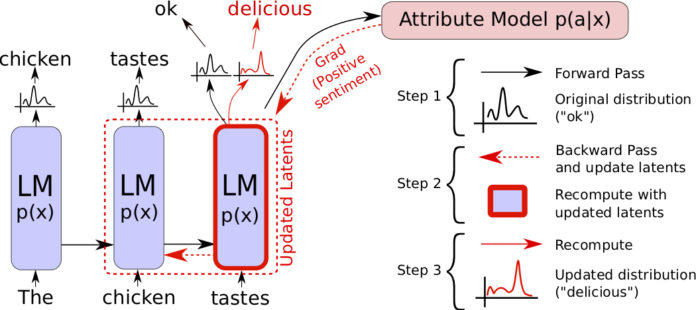
在每个时间步中,这个过程都会进行一次,也就是说表征了以往的值的隐层变量会被一次又一次地更新。
直观上讲,随着 PPLM 生成一个个词,它的文本表征也逐渐向着更有可能符合属性要求的方向发生变化(高 log(p(a|x)) ),同时也保持了语言模型本来的语言流畅度(在第二步中保持高 log(p(x),避免语言模型本来的表达能力被破坏)。
Uber AI 的研究人员们也对 PPLM 做了一些相关的说明:
首先,PPLM 的这种控制模式是可以调节的:对隐层文本表征的每一步变化的强度可以调节;当变化强度设为 0 的时候,这就是原本的语言模型。
其次,PPLM 假设原有的基础语言模型是自回归的,许多现代的语言模型都符合这个要求。实际上,如果语言模型是基于 Transformer 架构的,上面的这个方法就可以有高效的实现,因为以往的预测值只能通过 Transformer 的以往的键和值对未来的预测产生影响,和其它的激活值都无关,所以在前向传播中只有张量需要更新和传递。
以及,PPLM 中的采样器的实现,和上面提到的《Exponential convergence of Langevin distributions and their discrete approximations》以及 PPGN,arxiv.org/abs/1612.00005 中的实现有一些重要的不同,感兴趣的研究人员可以阅读论文原文具体了解
最后,Uber AI 这项研究中选用的基础语言模型是 345M 参数的 GPT-2.但对于其他的自回归语言模型也是有效的。
词袋属性模型
Uber AI 的研究人员们首先尝试了最简单的一类属性模型,词袋模型(Bag-of-words),计算方式也就是直白的「符合主题的似然度等于词袋中每个词单独的似然度的和」,换句话说就是含有越多词袋中的词,就认为句子符合属性的可能性越高。
在这个实验中,他们想要生成太空主题的文本,词袋中含有「planet、galaxy、space、universe」等等词汇。即便给定不同的开头,模型生成的几组结果都达到了预期效果。

同一主题、不同开头实验
在下一个实验中,他们用同样的开头、不同内容的词袋模型尝试生成不同的主题。我们可以看到,生成的文本带有词袋中的词的概率提升的同时,不在词袋中、但有相关性的词汇的出现概率也增加了。这是因为,PPLM 中更新文本表征的方式是向着目标方向的连贯自然的迁移,作者们也通过对照实验说明这种做法的效果比直接提升想要的关键词的出现频率的效果更好。

同一开头、不同主题实验
在苛刻的条件下,PPLM 的表现如何呢?这组实验中,给定和目标话题完全不相关的开头,比如「以各种动物/食物开头,主题是政治」。即便是这样奇怪的开头,PPLM 也能生成合理的句子。

有挑战性的开头和主题
判别器属性模型
词袋模型固然是一个简单直观的话题表征方式,但对于一些更复杂、深层次的属性,比如正面和负面情绪,我们总还是需要更复杂一些的模型的。这种时候我们就可以使用在标注数据集上训练出的分类模型。
Uber AI 的研究人员们设计的分类模型把原本的语言模型中提取出的嵌入表征作为输入,用一个单层分类器结构预测类别标签。这个模型中含有的参数可以不超过 5000 个,相比于语言模型的规模可谓不值一提。
这样得到的 PPLM-Discrim 模型生成正面和负面情感的文本效果如下图

多个属性模型联合使用
人类有能力在一段话中覆盖多种主题,PPLM 也可以。Uber AI 的研究人员们尝试了把多个词袋模型和一个分类模型一起使用,可以让一段话同时符合「冬天、政治、厨房」的主题,而且有正面情绪。图中第二段同时符合「计算机、幻想、钓鱼链接」主题。

多个属性模型联合,多主题文本生成避免语言模型生成有害文本
在前面的叙述和例子中我们都看到了,PPLM 架构可以使用任意可微的属性模型引导语言模型生成各种不同属性或者主题的文本。但在应用中我们还会遇到一种问题,由于大规模语言模型都是在海量的互联网文本上训练的,这些文本经常含有偏见或者使用不友善的(骂人)的词汇。论文 arxiv.org/abs/1908.07125 就展示了,如果用对抗性攻击的思路设计文本开头,可以让 GPT-2 续写出带有种族主义的段落。这种状况会限制语言模型的安全应用场景。
由于 PPLM 使用梯度来更新语言表征,解决这种问题就要简单得多,只需要训练一个恶意文本分类器,把它作为属性模型,然后使用负梯度更新语言表征,也就是减小生成文本符合属性的概率即可。研究人员们选用了能够让原本的 GPT-2 模型输出恶意文本的对抗性文本开头,在应用 PPLM 后,继续输出对抗性文本的概率从原来的 63.6% 降低到了 4.6%。不过,不仅确保模型的输出完全符合设计者的意图还需要更多后续研究,我们也需要用更多方法避免恶意的使用者反倒利用 PPLM 的特点专门生成恶意文本。
总结
在这项研究中,Uber AI 的研究人员们提出了可以在使用过程中引导大规模预训练语言模型输出不同主题、不同风格文本的 PPLM,而且可以灵活地搭配一个到多个词袋模型、小型判别式模型等等作为属性模型,在细粒度地控制生成文本内容和风格的同时,即保持了文本的合理和流畅,也避免了重新训练或者精细调节语言模型。PPLM 中的预训练语言模型可以使用各种自回归语言模型,属性模型也可以使用各种可微模型,这都意味着 PPLM 还有很大的使用空间。
阅读论文:Plug and Play Language Models: a Simple Approach to Controlled Text Generation,https://arxiv.org/abs/1912.02164
代码开源:
https://github.com/uber-research/PPLM (单独 PPLM)
https://github.com/huggingface/transformers/tree/master/examples/pplm (集成 Transformer)
Demo:https://transformer.huggingface.co/model/pplm
via https://eng.uber.com/pplm/,雷锋网 AI 科技评论编译
|







