晓推研发视频识别技术可以识别视频中的人物和物体,场景,特别在识别任明星人物方面,晓推还特别做了更加深入化的工作,如图1所示,我们的模型可以识别出视频中的两位明星与这两位明星的个人知识卡片。这项技术本身的意义超过了视频广告投放本身,可以扩展到安防与娱乐等其他行业,同时人物知识图谱的建立,也更加扩展该技术的可用性,这里介绍是视觉篇。

图1.
晓推通过自身标注了大量的明星图片,该过程由人工与无监督或者半监督模型的辅助之下完成。其中明星的识别可以直接使用现在较为成熟的CNN系列的网络,如ResNet,或者是更为简单的VggNet,这里晓推使用另一种方法,采用区域检测的方法,使用两种网络,一种是FCN,另一种是YOLO网络。这两种网络的架构如图2和图3所示。
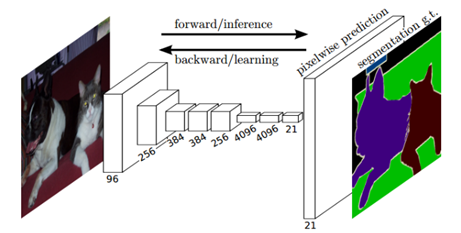
图2. FCN网络结构
FCN对图像进行像素级的分类,从而解决了语义级别的图像分割问题。与经典的CNN在卷积层使用全连接层得到固定长度的特征向量进行分类不同,FCN可以接受任意尺寸的输入图像,采用反卷积层对最后一个卷基层的特征图(feature map)进行上采样,使它恢复到输入图像相同的尺寸,从而可以对每一个像素都产生一个预测,同时保留了原始输入图像中的空间信息,最后奇偶在上采样的特征图进行像素的分类。FCN也会存在一些缺点:1.对像素与像素之间的关系并没有考虑到,忽略了在通常的基于像素分类的分割方法中使用的空间规整(spatial regularization)步骤,缺乏空间一致性。2.虽然8倍的上采样效果还可以,但还有待提高,不够精细,细节还有待提高。
YOLO 3的网络架构如图3所示,YOLO3借鉴了残差网络结构,形成更深的网络层次,以及多尺度检测,提升了mAP及小物体检测效果。如果采用COCO mAP50做评估指标(不是太介意预测框的准确性的话),YOLO3的表现相当惊人,如下图所示,在精确度相当的情况下,YOLOv3的速度是其它模型的3、4倍,不过如果要求更精准的预测边框,采用COCO AP做评估标准的话,YOLO3在精确率上的表现就弱了一些。v3毫无疑问现在成为了工程界首选的检测算法之一了,结构清晰,实时性好。
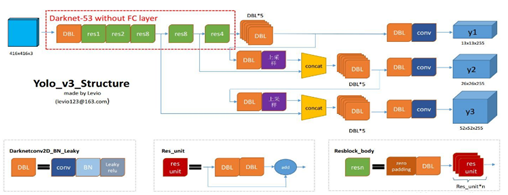
图3.
|







